正则表达式如何匹配一些特殊字符呢?
来源:13-8 正则分析获取名字和人数

EMP830
2019-09-01
import re
from urllib import request
class Spider():
#url="https://www.huya.com/g/lol"
url="https://www.huya.com/g/dn"
root_pattern='<span class="txt">([\s\S]*?)</li>'
# name_pattern='<i class="nick" title=\S*?>(\S*?)</i>'
name_pattern='<i class="nick" title=\S*?>(\S*?)<\/i>'
# num_pattern='<i class="js-num">(\d*?)</i>'
num_pattern='<i class="js-num">([\s\S]*?)</i>'
def __fetch_content(self):
r = request.urlopen(Spider.url)
htmls=r.read()
htmls=str(htmls,encoding='UTF-8')
return htmls
def analysis(self,htmls):
root_htmls=re.findall(Spider.root_pattern, htmls)
anchors=[]
for info in root_htmls:
name_htmls=re.findall(Spider.name_pattern,info)
if name_htmls==[]:
name_htmls=['匹配不到的名字========================================']
num_htmls=re.findall(Spider.num_pattern,info)
anchor={'name':name_htmls,'number':num_htmls}
anchors.append(anchor)
return anchors
def __refine(self,anchors):
l=lambda anchor:{
'name':anchor['name'][0].strip(),
'number':anchor['number'][0]}
a=1
return map(l,anchors)
def __sort(self,anchors):
anchors=sorted(anchors,key=self.__sort_seed, reverse=True)
return anchors
def __sort_seed(self,anchor):
r=re.findall('\d*',anchor['number'])
number=float(r[0])
if '万' in anchor['number']:
number=number*10000
return number
def __show(self,anchors):
for anchor in anchors:
print(anchor['name']+'----->'+anchor['number'])
def go(self):
htmls=self.__fetch_content()
anchors=self.analysis(htmls)
# print(anchors)
# anchors=list(self.__refine(anchors))
anchors=list(self.__refine(anchors))
#
anchors=self.__sort(anchors)
self.__show(anchors)
spider=Spider()
spider.go()
当我在爬取虎牙的时候我发现我的报错是 list index out of range
经过我debug 我发现如果有些主播的名字含有特殊字符 正则表达式是无法匹配到的 例如 ✿ 贝 尔 ✿
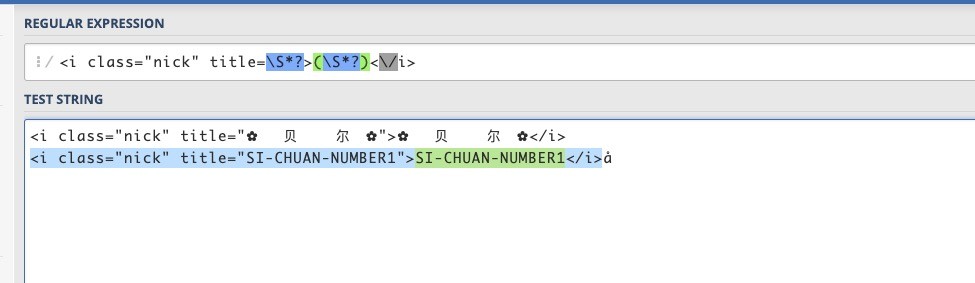
这样就会造成 正则表达式返回一个空的列表 [] 当我们在使用 'name':anchor['name'][0].strip(), 对列表进行访问的时候就会报错了
但是 有什么办法可以匹配到类似于 这些 ✿ 的特殊字符呢?
写回答
1回答
-

7七月
2019-09-05
你不需要匹配具体的特殊字符吧,你只需要匹配这些特殊字符两端的内容,然后获取到完整的 中间字符就行了。为什么要匹配特殊字符呢?
032020-05-22

相似问题