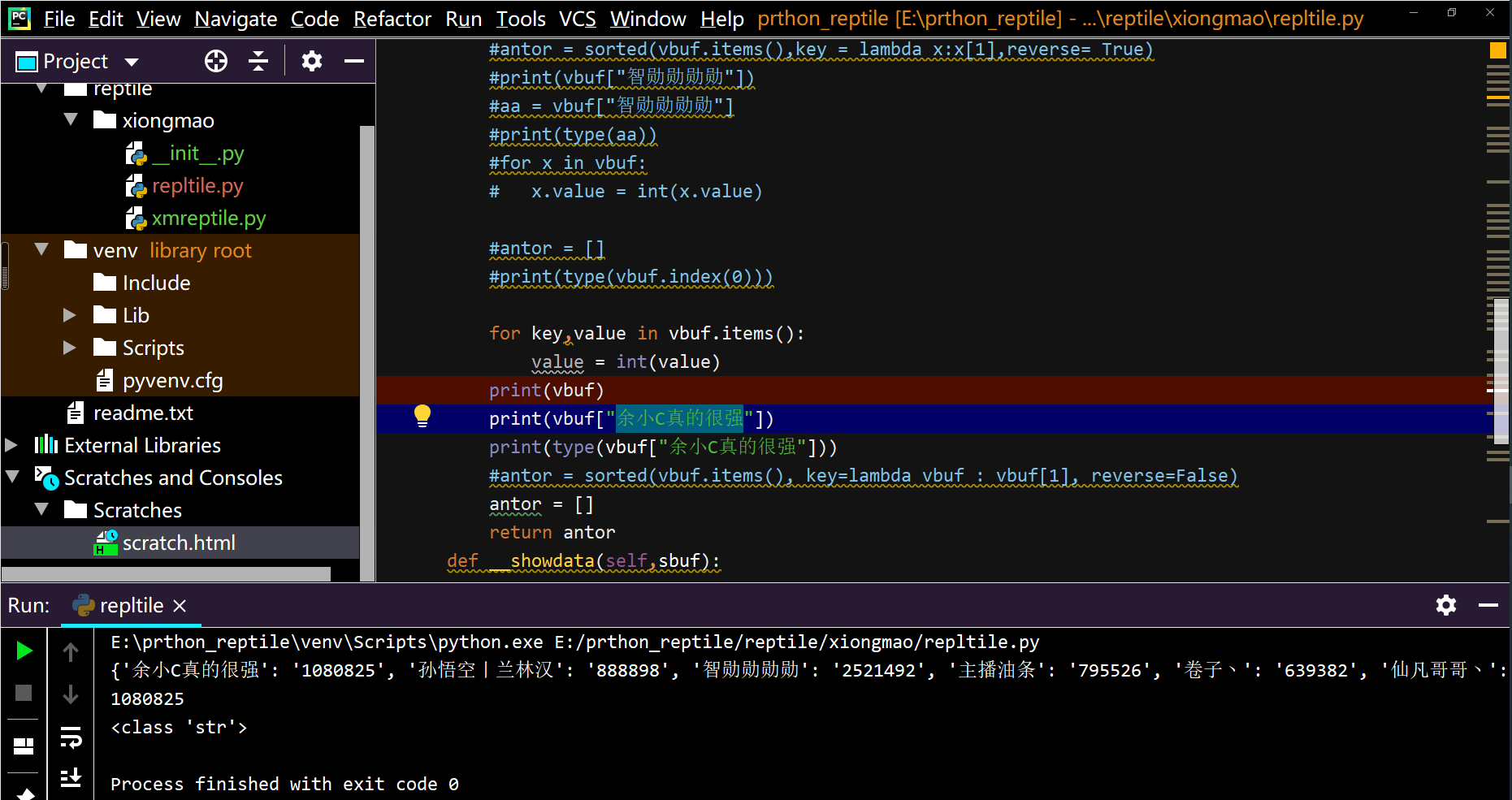
字典的value的类型打印的是str我不是我想要的int的类型
来源:13-8 正则分析获取名字和人数

慕婉清9566215
2020-02-15
from urllib import request
from io import BytesIO
import gzip
import re
import json
class Cl_requets():
url = 'https://www.douyu.com/g_LOL'
# * 匹配所有内容 ? 非贪婪模式 \s\S 匹配所有字符 () 组的概念 去掉两边的
root_partten = '"av":"avatar_v3([\s\S]*?)"topid"'
name_partten = '"nn":"([\s\S]*?)","od'
num_partten = '"ol":([\s\S]*?),"ot"'
def __fetch_content(self):
r = request.urlopen(Cl_requets.url)
html = r.read()
buff = BytesIO(html)
ff = gzip.GzipFile(fileobj= buff)
html = ff.read().decode('utf-8')
return html
def __analysis(self,htmls):
root_html = re.findall(Cl_requets.root_partten,htmls)
name = re.findall(Cl_requets.name_partten,str(root_html))
num = re.findall(Cl_requets.num_partten,str(root_html))
vbuf = dict(zip(name,num)) #列表转化为字典
#print(value)
#print(type(value))
#print(type(vbuf))
#print(vbuf)
return vbuf
def __sort(self,vbuf):
#antor = sorted(vbuf.items(),key = lambda x:x[1],reverse= True)
#print(vbuf["智勋勋勋勋"])
#aa = vbuf["智勋勋勋勋"]
#print(type(aa))
#for x in vbuf:
# x.value = int(x.value)
#antor = []
#print(type(vbuf.index(0)))
for key,value in vbuf.items():
value = int(value)
print(vbuf)
print(vbuf["余小C真的很强"])
print(type(vbuf["余小C真的很强"]))
#antor = sorted(vbuf.items(), key=lambda vbuf : vbuf[1], reverse=False)
antor = []
return antor
def __showdata(self,sbuf):
pass
#print(sbuf)
def go(self):
htmls = self.__fetch_content()
vdata = self.__analysis(htmls)
sortdata = self.__sort(vdata)
self.__showdata(sortdata)
dy_request = Cl_requets()
dy_request.go()
这里打印字典的valude的类型,为啥是 str 而不是 int 类型,我都给value类型强制转换啦
print(vbuf)
print(vbuf["余小C真的很强"])
print(type(vbuf["余小C真的很强"]))
```
写回答
1回答
-

7七月
2020-02-16
可否把问题简化一下,这个太大的段落不太容易理解你的问题
022020-02-16

相似问题