提取网页元素
来源:13-7 正则分析HTML

月光下洗衣
2020-11-22
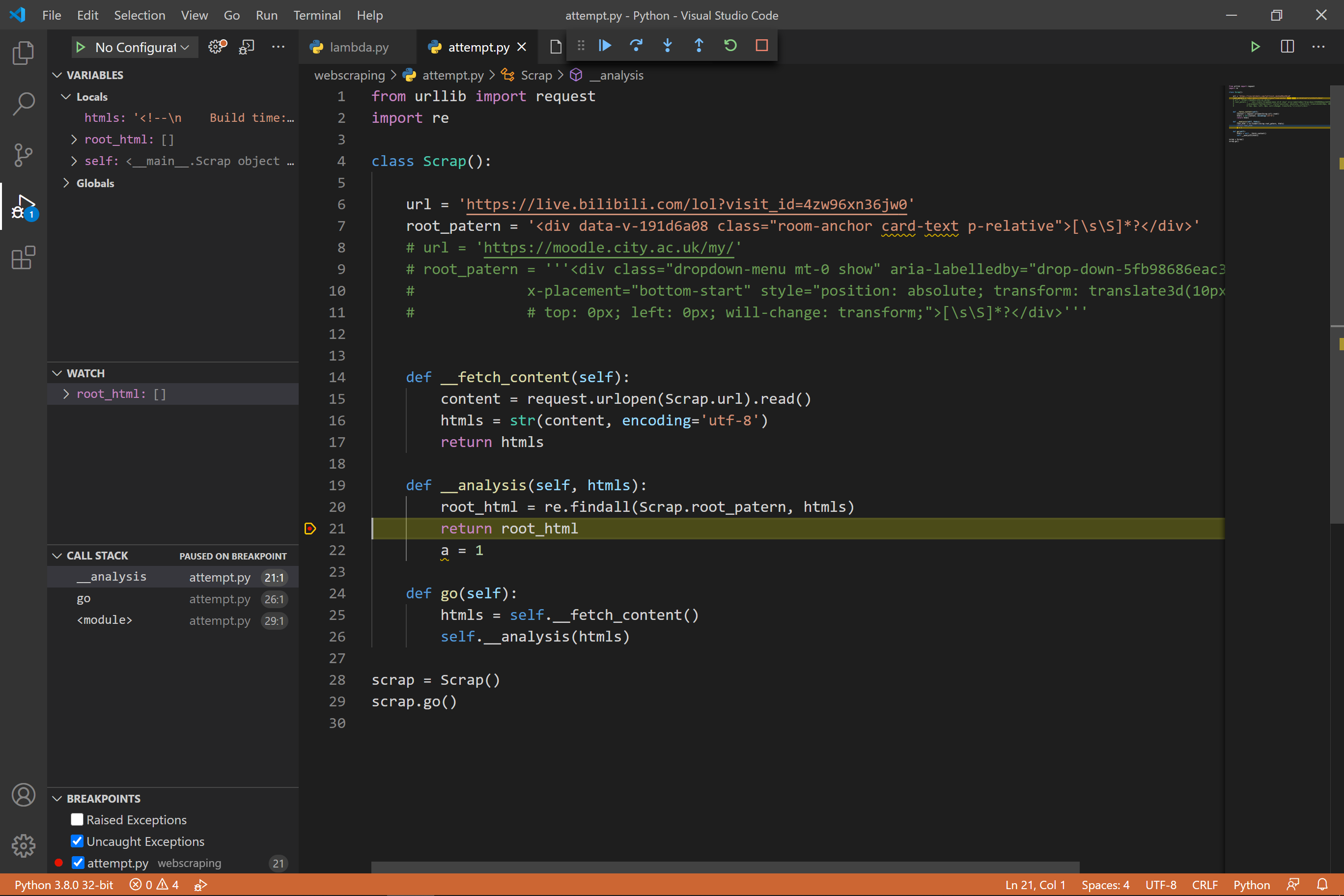 老师好,我想请问为什么我在提取网页元素的过程中发现返回的root_patern始终为空。__fetch_content()提取的htmls是成功的,但是后面的步骤就失败了。是我的正则表达式有问题吗?还是在代码调用上出了问题?
老师好,我想请问为什么我在提取网页元素的过程中发现返回的root_patern始终为空。__fetch_content()提取的htmls是成功的,但是后面的步骤就失败了。是我的正则表达式有问题吗?还是在代码调用上出了问题?
写回答
1回答
-

月光下洗衣
提问者
2020-11-22
012020-11-22
相似问题
提取网页元素
来源:13-7 正则分析HTML
月光下洗衣
2020-11-22
老师好,我想请问为什么我在提取网页元素的过程中发现返回的root_patern始终为空。__fetch_content()提取的htmls是成功的,但是后面的步骤就失败了。是我的正则表达式有问题吗?还是在代码调用上出了问题?
1回答
月光下洗衣
提问者
2020-11-22
相似问题