关于f1 score的问题
来源:10-7 ROC曲线

慕九州9175731
2019-09-17
老师你好,请问f1 score小于0.5的话,是否代表还不如随机分类?
写回答
1回答
-

liuyubobobo
2019-09-18
关键是你在比什么。
比如对于极度偏斜的数据,假设99.9%的健康样本和0.1%的患病样本。如果你的算法是直接预测所有的样本是健康的。通过这个课程的介绍,你应该知道了,得到的 f1 score 将为0。但是,这样一个算法,其实从准确率的角度,比随机强,因为随机的准确率大概是 50%。
在机器学习领域,说“谁不如谁”,一定要明确指标是什么。把两个算法的对应指标作比较。在上面的叙述中,我在用准确率作比较。但是,如果我们计算一个随机算法的f1_score。
使用课程中的例子,一个随机算法,应该大概是这样的。
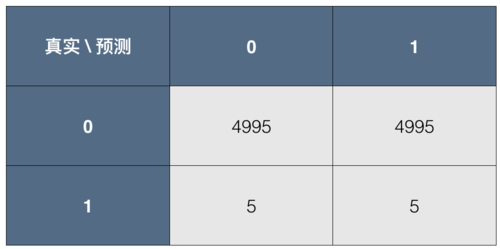
一共有 9990个健康样本,10个患病样本。随机算法在两类中各预测正确一半。
如果我没记算错,这个算法的f1_score 是 0.002 左右。所以,如果你的算法的 f1_score 小于 0.5,但比 0.002 大,从 f1_score 的角度看,是优于随机算法的。
我们通常说随机算法 50% 的正确率,是从准确度的角度看的,而不是从 f1_score 的角度看的。
继续加油!:)
00


相似问题