随机梯度下降法计算性能的疑问
来源:6-7 scikit-learn中的随机梯度下降法

Amberzy
2019-11-26
在视频里n_iters的取值为样本数量的整数倍,但是这样随机梯度下降法的计算量可能会比批量梯度下降法大吧,那为什么不直接用批量梯度下降呢?
写回答
2回答
-

liuyubobobo
2019-11-26
不会比梯度下降法大。课程中介绍了,随机梯度下降法的性能核心,在梯度的计算上。
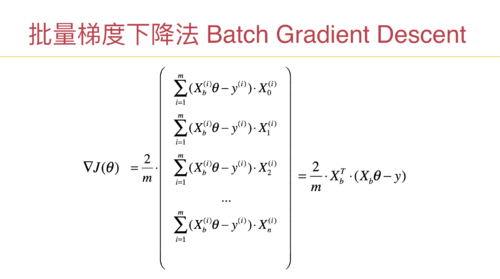
注意:每一项都有一个sigma,每个sigma都是对 m个样本操作,如果数据规模比较大,m可以是100万,1000万,计算按一次提督的性能开销都是巨大的。
而随机梯度法,计算梯度,只用一个样本。计算一次梯度,性能开销近乎是批量梯度下降法的 1/m。如果m是100万,就是一百万分之一。
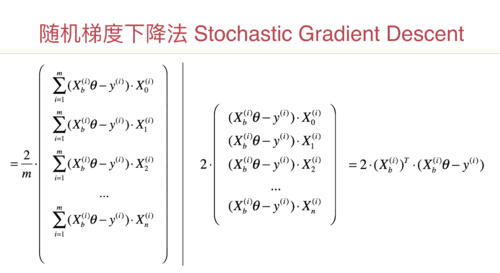
n_iters 虽然也是 m 的整数倍,但是整数倍,通常比批量梯度下降法的迭代次数要少很多,就可以得到比较令人满意的结果。印象中,课程里也针对一个数据集进行了实验,包括对使用的时间进行了计时。
如果感兴趣,你也可以尝试使用一个数据集,测试一下,获得同样的结果,两种梯度下降法的性能差别是怎样的?数据集越大,效果越明显。
继续加油!:)
222019-11-27 -

慕无忌5445318
2019-11-26
sigma sigma sigma sigma sigma sigma sigma sigma sigma sigma sigma sigma sigma sigma sigma sigma
00




相似问题