ConvergenceWarning
来源:9-8 OvR与OvO

ITMOCC
2021-01-19
老师,您好。现在sklearn默认的solver是lbfgs,我对digits数据集进行LogisticRegression或者LogisticRegressionCV,发现都不收敛。将solver换成liblinear发现都收敛了。查阅了sklearn文档,文档说liblinear适合小型数据集。我就想是不是digits数据集规模小了,只适合用liblinear。可是那些人造的数据那规模不更小吗?用的也是sklearn默认的solver,也没见报这种警告啊。我又用iris数据集测试,发现默认solver情况下LogisticRegression收敛,而
LogisticRegressionCV却不收敛,这又是为什么?同样改成liblinear后就都收敛了。
写回答
1回答
-

liuyubobobo
2021-01-19
首先,一个算法适合小数据集,不代表所有小数据集都一定有效。只是统计意义上,这个算法在小数据集上,作用的效果更好。
以 iris 数据及为例,我测试了一下,现在默认的 LogisticRegression 确实不收敛。
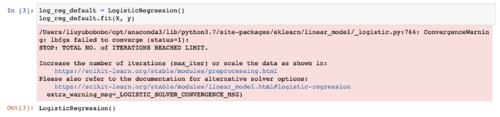
解决不收敛的方式,通常有两种,其实课程中都提及过:
1)增加迭代次数。所谓不收敛,是在有限次迭代中没有收敛。LogisticRegression 默认的迭代次数 max_iter 是 100,我试了一下,max_iter 设置为 1000 就可以收敛。

2)另一个方式非常建议,就是对数据做标准化。在讲线性回归的时候介绍过,对于一些算法,标准化虽然在理论上不影响最终的结果,但是会让搜索更容易进行。

继续加油!:)
042021-01-19



