为什么knn算法的k越小模型会越复杂?
来源:8-5 学习曲线

慕运维2948618
2018-01-22
knn不是计算出样本与每个样本的距离后,对前k个距离最近的样本进行投票,然后最高票胜出。那为什么说k越小越容易过拟合呢?
写回答
1回答
-
直观地理解,过拟合就是学习到了很多“局部信息”,或者是“噪音”,使得我们的模型中包含很多“不是规律的规律”。在knn算法中,k越小,就越有可能让我们的学习结果被“局部信息”所左右。在极端情况下,k=1,knn算法的结果只由离我们待预测样本最近的那个点决定,这使得我们knn的结果高概率被“有偏差的信息”或者“噪音”所左右,是一种过拟合。
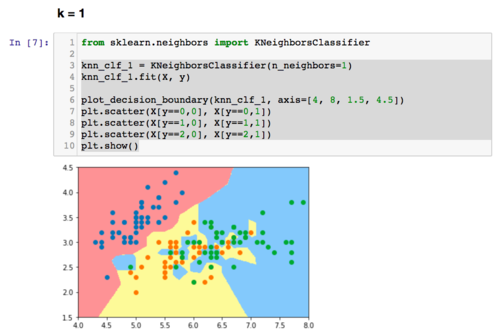
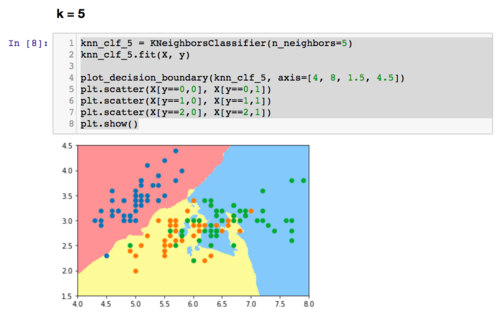
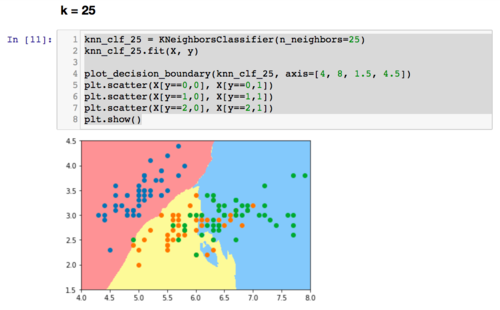
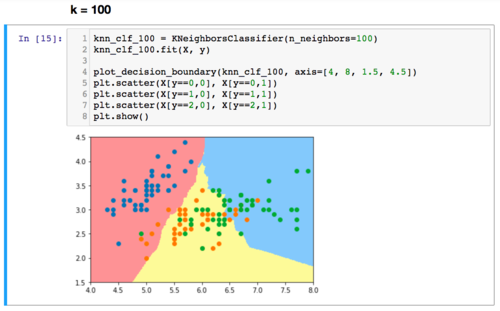
一个简单的可视化看过拟合的方式,是看决策边界的形状。“决策边界”的概念会在下一章介绍。决策边界越不规则,越有可能是过拟合。因为不规则的决策边界意味着数据的特征稍微有一点微小的变化,我们的分类算法就可能改变分类结果,也就是所谓的对噪音很明显。我们可以使用我们在这个课程中后续一直使用的plot_decision_boundary这个函数,来观察一下knn中,对k不同的取值,决策边界的不同。可以考虑看完下一章,再回头看下面的图示。在这里,我简单绘制了对于iris数据,knn中的k取值不同,决策边界的不同。很显然,k越小,决策边界越不规则:)
 1032021-05-19
1032021-05-19





相似问题