连接池的出错处理该怎么写?比如其中一个worker节点挂了。
来源:18-9 使用连接池链接爬虫集群

AItsuki
2019-11-17
在单机版爬虫中,老师说如果一个request请求失败,那么直接放弃这个request,因为对于一大堆数据来说一两个数据没爬到是能接受的。
但是在分布式爬虫中,可以开启多个worker节点,当其中一个节点挂了以后,连接池还是保存着这个已断开节点,并且会将节点分配给RequestProcessor,导致RequestProcessor去处理一个必然失败的Request。这样爬虫丢失的数据量就非常大了,如果开启两个节点,挂了一个,数据量是不是就丢了一半了。
这种情况应该怎么处理呢……
1回答
-

ccmouse
2019-11-21
这是个好问题。
就我们这个项目而言,失败了可以把request还回去,这样不至于丢。(https://git.imooc.com/coding-180/coding-180/src/master/crawler_distributed/worker/client/worker.go#L22)
为了防止继续丢,我们考虑再建立一个channel用来通知外面我这个链接挂了,让从连接池里面拿掉。(https://git.imooc.com/coding-180/coding-180/src/master/crawler_distributed/main.go#L85 )
或着再做一个健康检查goroutine,把不健康的链接拿掉等等。
这两处我们可以自己试试加上。
那么到了实际项目中,我们很可能不自己维护连接池,而是通过服务发现机制。云服务提供的load balancer,kubernetes本身,或这开源解决方案比如eureka,consul,zookeeper等,都能提供类似的能力。这里我们只是把request发送去到一个worker服务,这个worker服务本身维护了很多后面真正的节点进行分发,它会管理哪些节点活着,哪些节点死了,甚至动态增加减少节点。
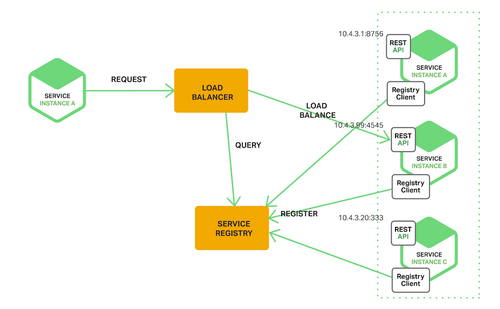
这个图来自一篇很好的文章:https://www.jianshu.com/p/1bf9a46efe7a
112019-12-02


相似问题