获取初始页问题
来源:15-1 获得初始页面内容

慕慕5064480
2020-03-05
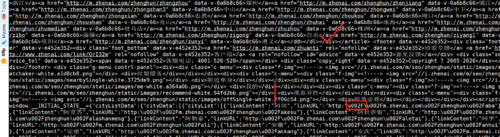
珍爱网http://m.zhenai.com/zhenghun 获取的源码有问题,http后面插入了unicode码,我用python倒是可以很方便的先过滤出unicode码然后decode为unicode-escape就解决问题了,Go语言不知道怎么实现,忘老师解惑。
写回答
3回答
-

慕慕5064480
提问者
2020-03-07
不好意思,下午有事,回复晚了。 其实就是个获取网页源码。代码就是您课程上面的。另外,我用Python不做处理只是request的话,也是一样的情况,我刚发现了问题,是我自己的问题,我看运行完代码运行结果直接跑源码底部了,这个源码前面是正常的,后半部分才是我说的那个问题。我自己大意了。
 00
00 -
慕慕5064480
提问者
2020-03-07
您好,老师。可能我描述的不够清楚,这个问题指向的是“获取初始页的内容”这个章节,问题是:“获取真爱网初始页的时候,url地址会显示如下:http:\u002F\u002Fwww.zhenai.com\u002Fzhenghun\u00。。。。。。
会有'u002F'这样的码,您也可以试一下。
012020-03-07 -

ccmouse
2020-03-07
具体碰到了什么问题?能解释一下“http后面插入了unicode码“是什么现象吗?
00


相似问题