量级1000万,测试heapify效率提升为什么不明显?
来源:8-5 Heapify 和 Replace

拓扑95
2019-07-25

写回答
1回答
-
我在我的环境下,用1000万的数据测试了一下,结果是这样的:
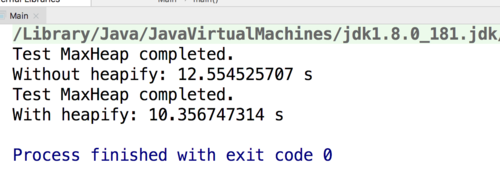
其实我觉得你的结果可以接受,因为O(n)和O(logn)的差距就是非常小的。在一般的OJ中,logn级别算法的差距,是根本测不出来的。所以,如果一个问题有O(n)的解,但是你的算法是O(nlogn)的,一定能通过。我没有见过可以卡得住logn级别差距算法的问题。
具体到语言执行层面,变数就更大了,和你的操作系统状态,编译器内部优化,都有关系。尤其是Java,本身执行在JVM中,JVM的实现会对算法性能产生影响,很难说JVM中有怎样的操作,导致了这样的结果。
如果不甘心,可以尝试多运行几遍程序,看看在你的环境下,是不是每次都是这样接近的结果?
不过整体,我不建议在这个问题上纠结了。如果真要纠结,我建议使用 C/C++,甚至是汇编,来实现相关逻辑,看到的性能结果,更接近逻辑运行的性能结果,而摒弃了更多语言层面,比如JVM的实现,等相关的影响。
这也就是我在这个课程一开始说的,不建议使用Python,JS等语言学习算法,尤其是探究算法性能的原因。脚本语言更是依赖解释器的实现。Java好很多,但毕竟在具体执行上,还是隔着JVM:)
继续加油!:)
122019-09-17


相似问题