process_nodes_list()函数的遍历好像不对
来源:14-7 分析和获取所有的版块 - 1

渔翁001
2019-12-19
原文你这样写的:
def process_nodes_list(nodes_list):
#将js的格式提取出url到list中
for item in nodes_list:
if “url” in item:
url_list.append(item[“url”])
if “children” in item:
process_nodes_list(item[“children”])
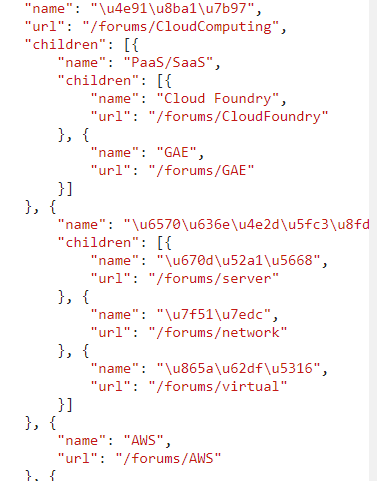
我分析了下数据里面,确实有的children下面的字典数据,没有url:值
所以上面遍历会把没有url的children的下一个children的值遗漏
所以是不是应该这样:
def process_nodes_list(nodes_list):
#将js的格式提取出url到list中
for item in nodes_list:
if “url” in item:
url_list.append(item[“url”])
if “children” in item:
process_nodes_list(item[“children”])
写回答
2回答
-

渔翁001
提问者
2019-12-21
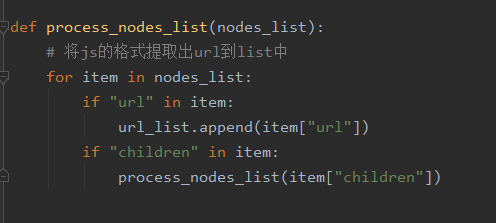
这里2个if应该时同级关系,您那边是下一级关系,如果下一级好像会漏了children下级url为空的再下一级比如下面的children,没有url,所以就遍历不到他的下级url了:
 012019-12-22
012019-12-22 -
渔翁001
提问者
2019-12-19
代码缩进没提现出来,应该是2个if是同级关系,不是下一级关系。
022019-12-21


相似问题