线程池执行完prase_list(帖子列表第一页)之后就退出了,不会执行prase_topic和prase_author
来源:9-4 京东的商品详情页接口分析

郭少宇
2020-02-11

以下是我的完整代码,包括CSDN_spider代码和models代码,CSDN网站用户网页发生了变化,因此用户数据抓取的代码和models中用户表结构进行了调整,如果代码有改正或改进的地方也请您提出:
spider代码:
"""
抓取
解析
存储
"""
import re
import ast
import requests
import time
from urllib import parse
from datetime import datetime
from scrapy import Selector
from selenium import webdriver
from concurrent.futures import ThreadPoolExecutor
from csdn_spider.models import *
domain = "https://bbs.csdn.net"
author_domain = "https://me.csdn.net"
def get_nodes_json():
left_menu_text = requests.get("https://bbs.csdn.net/dynamic_js/left_menu.js?csdn").text
nodes_str_match = re.search("forumNodes: (.*])", left_menu_text)
if nodes_str_match:
nodes_str = nodes_str_match.group(1).replace("null", "None")
nodes_list = ast.literal_eval(nodes_str)
return nodes_list
return []
url_list = []
def process_nodes_list(nodes_list):
#将js的格式提取出url到list中
for item in nodes_list:
if "url" in item:
if item["url"]:
url_list.append(item["url"])
if "children" in item:
process_nodes_list(item["children"])
def get_level1_list(nodes_list):
level1_url = []
for item in nodes_list:
if "url" in item and item["url"]:
level1_url.append(item["url"])
return level1_url
def get_last_urls():
#获取最终需要抓取的url
nodes_list = get_nodes_json()
process_nodes_list(nodes_list)
level1_url = get_level1_list(nodes_list)
last_urls = []
for url in url_list:
if url not in level1_url:
last_urls.append(url)
all_urls = []
for url in last_urls:
all_urls.append(parse.urljoin(domain, url))
all_urls.append(parse.urljoin(domain, url+"/recommend"))
all_urls.append(parse.urljoin(domain, url+"/closed"))
return all_urls
def parse_topic(url):
#获取帖子的详情以及回复
print("开始获取帖子详情页:{}".format(url))
topic_id = url.split("/")[-1]
res_text = requests.get(url,cookies=cookie_dict).text
sel = Selector(text=res_text)
all_divs = sel.xpath("//div[starts-with(@id, 'post-')]")
topic_item = all_divs[0]
content = topic_item.xpath(".//div[@class='post_body post_body_min_h']").extract()[0]
praised_nums = topic_item.xpath(".//label[@class='red_praise digg']//em/text()").extract()[0]
jtl_str = topic_item.xpath(".//div[@class='close_topic']/text()").extract()[0]
jtl = 0.0
jtl_match = re.search("(\d+\.+\d+)%", jtl_str)
if jtl_match:
jtl = float(jtl_match.group(1))
existed_topics = Topic.select().where(Topic.id == topic_id)
if existed_topics:
topic = existed_topics[0]
topic.content = content
topic.jtl = jtl
topic.praised_nums = int(praised_nums)
topic.save()
def answer_topic(answer_divs):
for answer_item in answer_divs:
answer = Answer()
answer.topic_id = topic_id
author_info = answer_item.xpath(".//div[@class='nick_name']//a[1]/@href").extract()[0]
author_id = author_info.split("/")[-1]
create_time = answer_item.xpath(".//label[@class='date_time']/text()").extract()[0]
create_time = datetime.strptime(create_time, "%Y-%m-%d %H:%M:%S")
answer.author = author_id
answer.create_time = create_time
praised_nums = answer_item.xpath(".//label[@class='red_praise digg']//em/text()").extract()[0]
answer.parised_nums = int(praised_nums)
content = answer_item.xpath(".//div[@class='post_body post_body_min_h']").extract()[0]
answer.content = content
answer_id = answer_item.xpath(".//@data-post-id").extract()[0]
answer.answer_id = answer_id
existed_answer = Answer.select().where(Answer.answer_id == answer_id)
if existed_answer:
answer.save()
else:
answer.save(force_insert=True)
answer_divs = all_divs[1:]
executor.submit(answer_topic,answer_divs)
def answer_next_page_function(answer_next_page):
if answer_next_page:
try:
answer_next_page_url = parse.urljoin(domain,answer_next_page[0])
print("开始获取帖子回复下一页:{}".format(answer_next_page_url))
res_text_next = requests.get(answer_next_page_url,cookies=cookie_dict).text
sel_next = Selector(text=res_text_next)
next_answer_divs = sel_next.xpath("//div[starts-with(@id, 'post-')]")
answer_topic(next_answer_divs)
new_answer_next_page = sel_next.xpath("//div[@id='bbs_title_bar']/div[@class='mod_fun_wrap clearfix']/div/div[@class='page_nav']/a[@class='pageliststy next_page']/@href").extract()
if len(new_answer_next_page) % 2 is 0:
new_answer_next_page_list = []
new_answer_next_page_list.append(new_answer_next_page[1])
executor.submit(answer_next_page_function,new_answer_next_page)
else:
pass
except IndexError as e:
pass
else:
pass
answer_next_page = sel.xpath("//div[@class='page_nav']/a[@class='pageliststy next_page']/@href").extract()
executor.submit(answer_next_page_function,answer_next_page)
def parse_author(url):
print("开始获取用户:{}".format(url))
author_id = url.split("/")[-1]
# 获取用户的详情
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36",
}
res_text = requests.get(url, headers=headers,cookies=cookie_dict_author).text
sel = Selector(text=res_text)
author = Author()
author.id = author_id
try:
author_name = sel.xpath("//p[@class='lt_title']/text()").extract()[0]
author.author_name = author_name.strip()
follower_nums_pre1 = sel.xpath("//div[@class='fans']/a/span/text()").extract()[0]
follower_nums_pre2 = follower_nums_pre1.replace("k+","000").replace("w+","0000")
author.follower_nums = int(follower_nums_pre2)
following_nums_pre1 = sel.xpath("//div[@class='att']/a/span/text()").extract()[0]
following_nums_pre2 = following_nums_pre1.replace("k+","000").replace("w+","0000")
author.following_nums = int(following_nums_pre2)
all_li_urls = sel.xpath("//ul[@class='me_chanel_list clearfix']/li/a/@href").extract()
blog_url = parse.urljoin(author_domain,all_li_urls[0])
resource_url = parse.urljoin(author_domain,all_li_urls[1])
forum_url = parse.urljoin(author_domain,all_li_urls[2])
reply_url = parse.urljoin(author_domain,all_li_urls[4])
column_url = parse.urljoin(author_domain,all_li_urls[6])
res_text_blog = requests.get(blog_url, headers=headers,cookies=cookie_dict_author).text
sel_blog = Selector(text=res_text_blog)
blog_grade_use = sel_blog.xpath("//div[@class='me_chanel_det_item level']/svg/use").extract()
blog_grade_str = re.search("#csdnc-bloglevel-(.{0,1})", blog_grade_use[0])
blog_grade = blog_grade_str.group(1)
blog_nums_str = sel_blog.xpath("//div[@class='me_chanel_det_item access']/a/span/text()").extract()[0]
blog_nums = blog_nums_str.replace("k+","000").replace("w+","0000").strip()
blog_rank_str = sel_blog.xpath("//div[@class='me_chanel_det_item access']/span/text()").extract()[0]
blog_rank = blog_rank_str.replace("k+","000").replace("w+","0000").strip()
author.blog_nums = int(blog_nums)
author.blog_grade = int(blog_grade)
author.blog_rank = int(blog_rank)
res_text_resource = requests.get(resource_url, headers=headers,cookies=cookie_dict_author).text
sel_resource = Selector(text=res_text_resource)
resource_grade_use = sel_resource.xpath("//div[@class='me_chanel_det_item level']/svg/use").extract()
resource_grade_str = re.search("#csdnc-dlevel-(.{0,1})", resource_grade_use[0])
resource_grade = resource_grade_str.group(1)
resource_nums_str = sel_resource.xpath("//div[@class='me_chanel_det_item access']/a/span/text()").extract()[0]
resource_nums = resource_nums_str.replace("k+","000").replace("w+","0000").strip()
resources_download_nums_str = sel_resource.xpath("//div[@class='me_chanel_det_item access']/span/text()").extract()[0]
resources_download_nums = resources_download_nums_str.replace("k+","000").replace("w+","0000").strip()
author.resource_nums = int(resource_nums)
author.resource_grade = int(resource_grade)
author.resources_download_nums = int(resources_download_nums)
res_text_forum = requests.get(forum_url, headers=headers,cookies=cookie_dict_author).text
sel_forum = Selector(text=res_text_forum)
forum_grade_use = sel_forum.xpath("//div[@class='me_chanel_det_item level']/svg/use").extract()
forum_grade_str = re.search("#csdnc-bbslevel-(.{0,1})", forum_grade_use[0])
forum_grade = forum_grade_str.group(1)
forum_info = sel_forum.xpath("//div[@class='me_chanel_det_item access']/span/text()").extract()
forum_nums = forum_info[0].replace("k+","000").replace("w+","0000").strip()
forum_answer_nums = forum_info[1].replace("k+","000").replace("w+","0000").strip()
forum_jtl_str = forum_info[2]
forum_jtl_match = re.search("(\d+\.+\d+)%", forum_jtl_str)
try:
forum_jtl = float(forum_jtl_match.group(1))
except:
forum_jtl = 0.0
author.forum_nums = int(forum_nums)
author.forum_grade = int(forum_grade)
author.forum_answer_nums = int(forum_answer_nums)
author.forum_jtl = forum_jtl
blink_nums = sel.xpath("//a[@class='tab_item tab_item_click']/label/span[@class='count']/text()").extract()
if blink_nums:
author.blink_nums = int(blink_nums[0].replace("k+","000").replace("w+","0000").strip())
else:
author.blink_nums = 0
res_text_reply = requests.get(reply_url, headers=headers,cookies=cookie_dict_author).text
sel_reply = Selector(text=res_text_reply)
reply_grade_use = sel_reply.xpath("//div[@class='me_chanel_det_item level']/svg/use").extract()
reply_grade_str = re.search("#csdnc-alevel-(.{0,1})", reply_grade_use[0])
reply_grade = reply_grade_str.group(1)
reply_info = sel_reply.xpath("//div[@class='me_chanel_det_item access']/span/text()").extract()
question_nums = reply_info[0].replace("k+","000").replace("w+","0000").strip()
reply_nums = reply_info[1].replace("k+","000").replace("w+","0000").strip()
author.question_nums = int(question_nums)
author.reply_grade = int(reply_grade)
author.reply_nums = int(reply_nums)
res_text_column = requests.get(column_url, headers=headers,cookies=cookie_dict_author).text
sel_column = Selector(text=res_text_column)
column_info = sel_column.xpath("//div[@class='sub_button']/a/span/text()").extract()
column_nums = column_info[0].replace("k+","000").replace("w+","0000").strip()
following_column_nums = column_info[1].replace("k+","000").replace("w+","0000").strip()
author.column_nums = int(column_nums)
author.following_column_nums = int(following_column_nums)
existed_author = Author.select().where(Author.id == author_id)
if existed_author:
author.save()
else:
author.save(force_insert=True)
except IndexError as e:
pass
def parse_list(url):
print("开始获取帖子列表页:{}".format(url))
res_text = requests.get(url,cookies=cookie_dict).text
sel = Selector(text=res_text)
all_trs = sel.xpath("//table[@class='forums_tab_table']//tbody//tr")
for tr in all_trs:
topic = Topic()
if tr.xpath(".//td[1]/span/text()").extract():
status = tr.xpath(".//td[1]/span/text()").extract()[0]
topic.status = status
if tr.xpath(".//td[2]/em/text()").extract():
score = tr.xpath(".//td[2]/em/text()").extract()[0]
topic.score = int(score)
topic_url = parse.urljoin(domain, tr.xpath(".//td[3]/a[contains(@class,'forums_title')]/@href").extract()[0])
topic_id = topic_url.split("/")[-1]
topic_title = tr.xpath(".//td[3]/a[contains(@class,'forums_title')]/text()").extract()[0]
author_url = parse.urljoin(author_domain,tr.xpath(".//td[4]/a/@href").extract()[0])
author_id = author_url.split("/")[-1]
create_time_str = tr.xpath(".//td[4]/em/text()").extract()[0]
create_time = datetime.strptime(create_time_str, "%Y-%m-%d %H:%M")
answer_info = tr.xpath(".//td[5]/span/text()").extract()[0]
answer_nums = answer_info.split("/")[0]
click_nums = answer_info.split("/")[1]
last_time_str = tr.xpath(".//td[6]/em/text()").extract()[0]
last_time = datetime.strptime(last_time_str, "%Y-%m-%d %H:%M")
topic.id = int(topic_id)
topic.title = topic_title
topic.author = author_id
topic.click_nums = int(click_nums)
topic.answer_nums = int(answer_nums)
topic.create_time = create_time
topic.last_answer_time = last_time
existed_topics = Topic.select().where(Topic.id == topic_id)
if existed_topics:
topic.save()
else:
topic.save(force_insert=True)
executor.submit(parse_topic,topic_url)
executor.submit(parse_author,author_url)
next_page_topic = sel.xpath("//div[@class='forums_table_c']/table/thead/tr/td/div/div[@class='page_nav']/a[@class='pageliststy next_page']/@href").extract()
if next_page_topic:
really_page_str = re.search("page=(.*)",next_page_topic[0])
really_page = really_page_str.group(1)
if len(next_page_topic) % 2 is 1 and really_page is 2:
next_page_topic_url = parse.urljoin(domain,next_page_topic[0])
print("开始获取帖子列表页下一页:{}".format(next_page_topic_url))
executor.submit(parse_list,next_page_topic_url)
elif len(next_page_topic) % 2 is 0:
next_page_topic_url = parse.urljoin(domain,next_page_topic[1])
print("开始获取帖子列表页下一页:{}".format(next_page_topic_url))
executor.submit(parse_list,next_page_topic_url)
else:
pass
if __name__ == "__main__":
browser = webdriver.Chrome(executable_path="D:\Python\webdriver\chromedriver.exe")
browser.get("https://bbs.csdn.net/")
time.sleep(10)
cookies1 = browser.get_cookies()
cookie_dict = {}
for item in cookies1:
cookie_dict[item["name"]] = item["value"]
browser = webdriver.Chrome(executable_path="D:\Python\webdriver\chromedriver.exe")
browser.get("https://me.csdn.net/")
time.sleep(10)
cookies2 = browser.get_cookies()
cookie_dict_author = {}
for item in cookies2:
cookie_dict_author[item["name"]] = item["value"]
executor = ThreadPoolExecutor(max_workers=10)
all_urls = get_last_urls()
for url in all_urls:
executor.submit(parse_list,url)
models代码:
from peewee import *
db = MySQLDatabase("spider", host="127.0.0.1", port=3306, user="root", password="1234")
class BaseModel(Model):
class Meta:
database = db
#设计数据表的时候有几个重要点一定要注意
"""
char类型, 要设置最大长度
对于无法确定最大长度的字段,可以设置为Text
设计表的时候 采集到的数据要尽量先做格式化处理
default和null=True
"""
class Topic(BaseModel):
title = CharField()
content = TextField(default="") #帖子内容
id = IntegerField(primary_key=True)
author = CharField()
create_time = DateTimeField()
answer_nums = IntegerField(default=0)
click_nums = IntegerField(default=0)
praised_nums = IntegerField(default=0) #点赞数量
jtl = FloatField(default=0.0) # 结帖率
score = IntegerField(default=0) # 赏分
status = CharField() # 状态
last_answer_time = DateTimeField()
class Answer(BaseModel):
answer_id = IntegerField(primary_key=True)
topic_id = IntegerField()
author = CharField()
content = TextField(default="")
create_time = DateTimeField()
parised_nums = IntegerField(default=0) #点赞数
class Author(BaseModel):
id = CharField(primary_key=True)
author_name = CharField()
follower_nums = IntegerField(default=0) # 粉丝数
following_nums = IntegerField(default=0) # 关注数
blog_nums = IntegerField(default=0)
blog_grade = IntegerField(default=0)
blog_rank = IntegerField(default=0)
resources_nums = IntegerField(default=0)
resources_grade = IntegerField(default=0)
resources_download_nums = IntegerField(default=0)
forum_nums = IntegerField(default=0)
forum_grade = IntegerField(default=0)
forum_answer_nums = IntegerField(default=0)
forum_jtl = IntegerField(default=0)
blink_nums = IntegerField(default=0)
reply_grade = IntegerField(default=0)
question_nums = IntegerField(default=0)
reply_nums = IntegerField(default=0)
column_nums = IntegerField(default=0)
following_column_nums = IntegerField(default=0)
if __name__ == "__main__":
db.create_tables([Topic, Answer, Author])
# db.create_tables([Topic, Answer])
写回答
1回答
-
main中加入这个
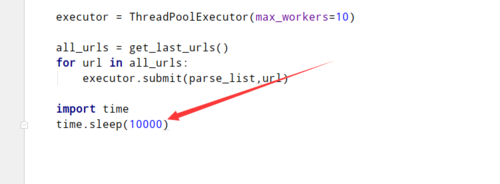 我这里试过这样可以进入parse_topic和author042020-02-13
我这里试过这样可以进入parse_topic和author042020-02-13

 我这里试过这样可以进入parse_topic和author
我这里试过这样可以进入parse_topic和author相似问题