代码问题
来源:9-5 通过requests完成京东详情页数据的获取

慕盖茨6398518
2020-02-23


写回答
5回答
-

慕盖茨6398518
提问者
2020-02-24
老师 这个不是标准的格式要怎么改 才可以变成标准的格式
162020-02-27 -
慕盖茨6398518
提问者
2020-02-29
这是那个json问题
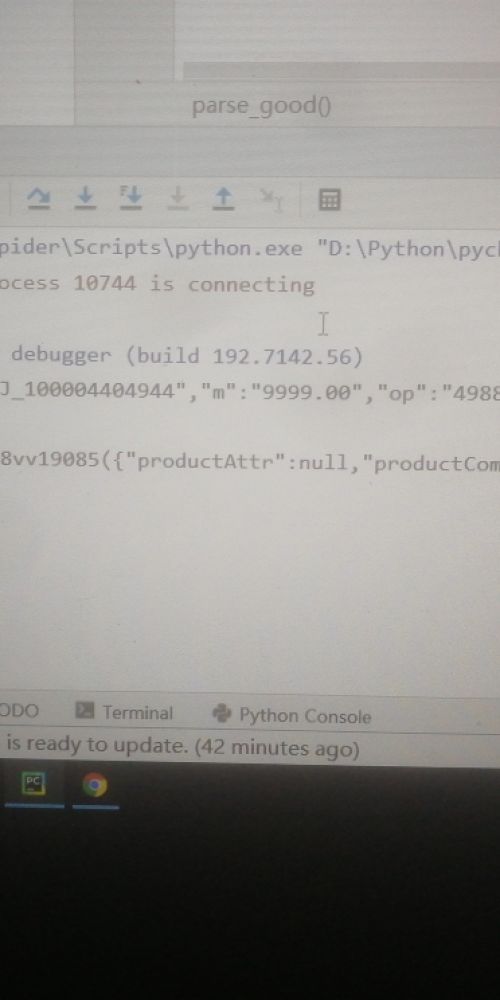
第一个str可以Json.loads
第二个str不可以json.loads00 -
慕盖茨6398518
提问者
2020-02-27
import json import requests from scrapy import Selector headers = { "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "accept-encoding": "gzip, deflate, br", "accept-language": "zh-CN,zh;q=0.9", "cookie": "__jdu=167283369; shshshfpa=822cd294-4734-6cd8-3a38-cc3e5e79bb5d-1579170000; shshshfpb=vaVc5UwnNRfqq2KInW57h4g%3D%3D; areaId=27; ipLoc-djd=27-2376-50230-0; PCSYCityID=CN_610000_610100_610112; jwotest_product=99; user-key=812511eb-181a-4a3f-a7d6-e1d719bbebc0; cn=0; unpl=V2_ZzNtbUVWSh18DUUEK0pUUmIDRVxLVRYRfQlDViwZDAI0AUFYclRCFnQUR1dnGVoUZwAZWEBcQBNFCEdkeBBVAWMDE1VGZxpFK0oYEDpBA04%2bR0ICLFYTHHMME1N7S1hSMwYUCEsEERB8D0BcextfDWUAR15AZ3MWdThGVUsZWwNkChBfRV9zJXI4dmRyG14BYQciXHJWc1chVEVRfR5bDCoDFVtBXkEXcgB2VUsa; __jdv=76161171|haosou-pinzhuan|t_288551095_haosoupinzhuan|cpc|0a875d61c5fe47d8bc48679132932d23_0_6089842aab9f41f083d59043f1a6b3b4|1581914608013; __jda=76161171.167283369.1579169996.1581914608.1581921361.9; __jdc=76161171; shshshfp=0fce42257fbb1fd4052bc6162b385b17; __jdb=76161171.4.167283369|9.1581921361; shshshsID=10ddca68cb9bc4782ac0542dfdb5c423_4_1581921643473; JSESSIONID=90C2E7A4E4E00B933F39FD85E1040D60.s1", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36", "referer": "https://item.jd.com/100004404944.html", "sec-fetch-dest": "script", "sec-fetch-mode": "no-cors", "sec-fetch-site": "same-site", } # print(requests.get("https://p.3.cn/prices/mgets?area=27_2376_50230_0&skuIds=J_100004404944&source=item-pc").text)#打印数据 # res = requests.get( # "https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv19085&productId=100004404944&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1", # headers=headers) def parse_good(good_id): good_url_template = "https://item.jd.com/{}.html".format(good_id) html = requests.get(good_url_template).text sel = Selector(text=html) name = "".join(sel.xpath("//div[@class = 'sku-name']/text()").extract()[1]).strip() price_text = requests.get("https://p.3.cn/prices/mgets?area=27_2376_50230_0&skuIds=J_{}&source=item-pc".format(good_id)).text.strip() price_json = json.loads(price_text) if price_json: price = float(price_json[0]["p"]) #获取商品评价信息 evaluate_url = "https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv19085&productId={}&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&fold=1".format(good_id, 0) evaluate_text = requests.get(evaluate_url, headers=headers).text.strip() # evaluate_json = json.loads(evaluate_text) pass if __name__ == "__main__": parse_good(100004404944)082020-03-03 -
慕盖茨6398518
提问者
2020-02-25

是这个样子的00 -

bobby
2020-02-24
在调用json.loads前先打印看看返回的内容是不是合法的json格式字符串
012020-02-29



相似问题