识别的时候中文乱码了
来源:13-3 Haar+Tesseract进行车牌识别

山野小花曳风雨
2025-02-21
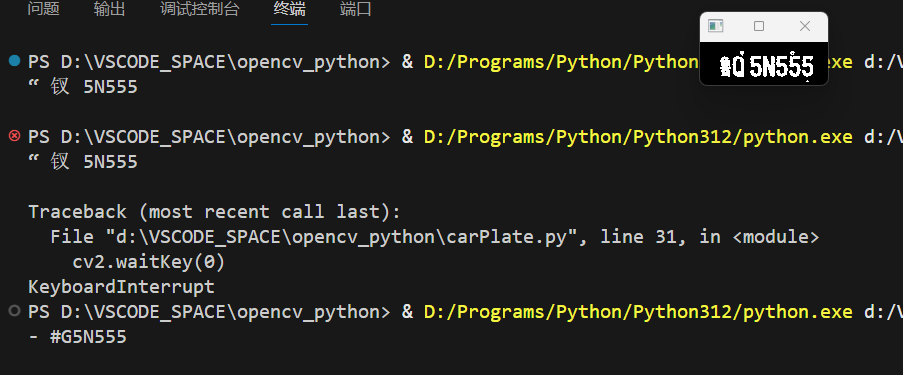 我这边lang=‘eng’ 时识别到的是#G5N555。lang='chi_sim+eng’时,识别到了中文乱码:如上图第一次跟第二次识别到的。请问这里中文乱码怎么处理?
我这边lang=‘eng’ 时识别到的是#G5N555。lang='chi_sim+eng’时,识别到了中文乱码:如上图第一次跟第二次识别到的。请问这里中文乱码怎么处理?
代码如下:
ret,roi_bin = cv2.threshold(roi, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)# cv2.THRESH_BINARY
codeString = pytesseract.image_to_string(roi_bin,lang='chi_sim+eng',config='--psm 8 --oem 3')#lang='eng'
print(codeString)
写回答
1回答
-

李超
2025-02-21
这个OCR库确实发展的比较慢,准确度还是不高,对中文支持也一般。我推荐你另外一个库吧,比这个好用,百度开源的叫 PaddleOCR,非常好用。
00

相似问题
如何在一幅大图中识别目标?
回答 1
opencv能做花屏识别吗
回答 1