关于filtered duplicate request的疑惑?
来源:7-7 职位数据入库-1

慕粉1946152704
2019-09-25
老师,下面日志中这个filtered duplicate request让我很疑惑:
这些request看上去像是在 dont_filter=False 的情况下被过滤掉的,但是我的spider脚本如下: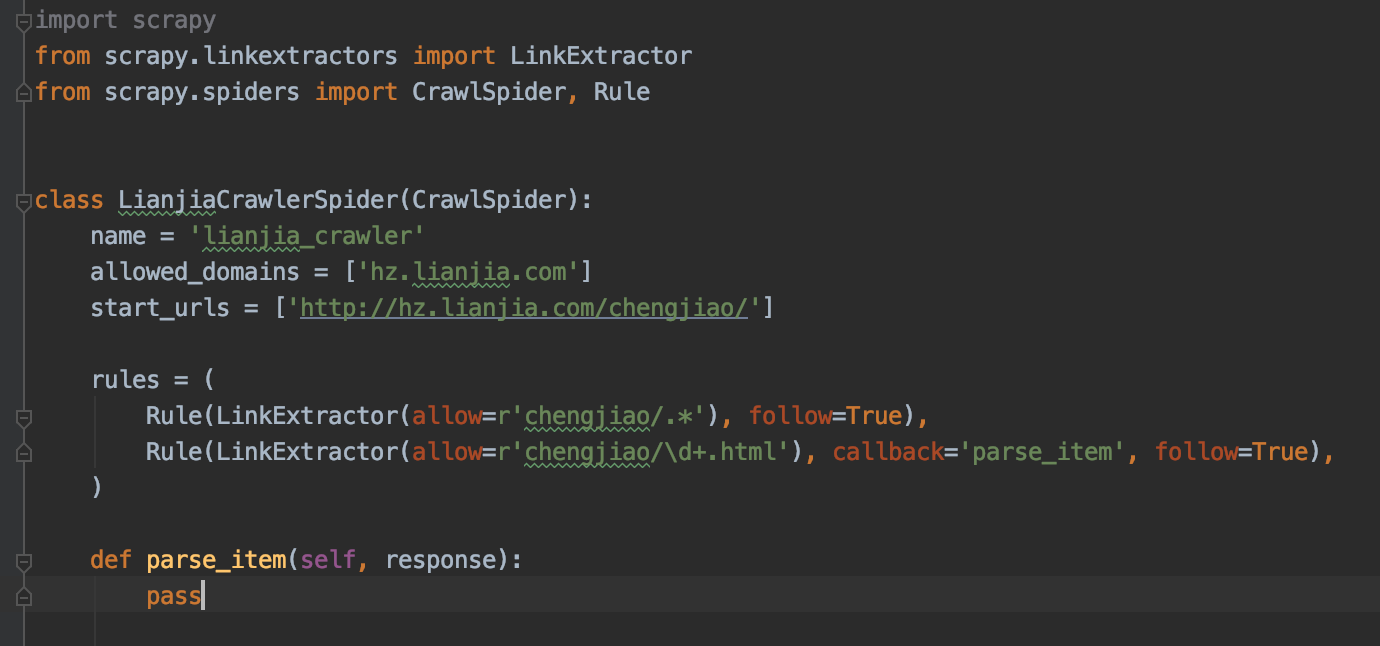
这些被过滤掉的URL, 例如 hz.lianjia.com/chengjiao/xihu/ 明明是第一次取,却被filtered,看上去很像是由于和 hz.lianjia.com/chengjiao/ 重了而被去重的.
但是这两个URL明显是不一样的.不符合scrapy的去重规则呀, 请问老师这个URL被filtered的原因是什么?
写回答
3回答
-
这种url明显不是一个url,指纹肯定不一样。如果说第一个访问后第二个不会访问了需要确保一下是不是第二个url已经访问过导致这个url的指纹会被放到缓存中
012019-09-26 -

qq_慕侠6486208
2021-04-27
请问你这个问题解决了吗?我也遇到了类似的问题,找不到解决的办法
012021-04-27 -

bobby
2019-09-28
你试一下在每个request的参数中加上参数 dont_filter=False试试会不会被过滤掉
012019-09-28


相似问题