将selenium集成到scrapy后,爬取cnblogs下载图片报错了。集成后怎么解决图片下载问题呢?
来源:9-4 selenium集成到scrapy中

楚人长铗
2020-02-09
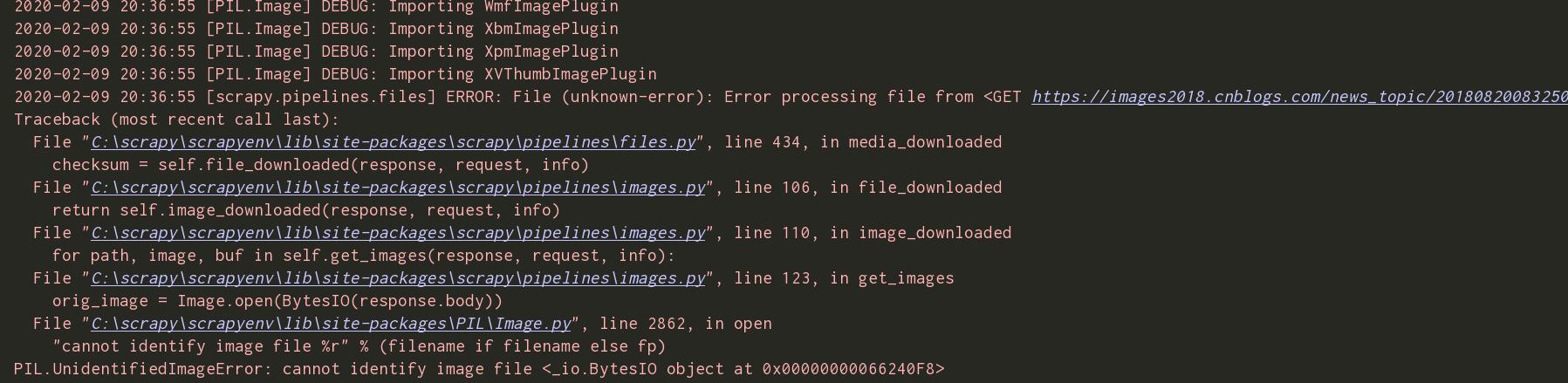

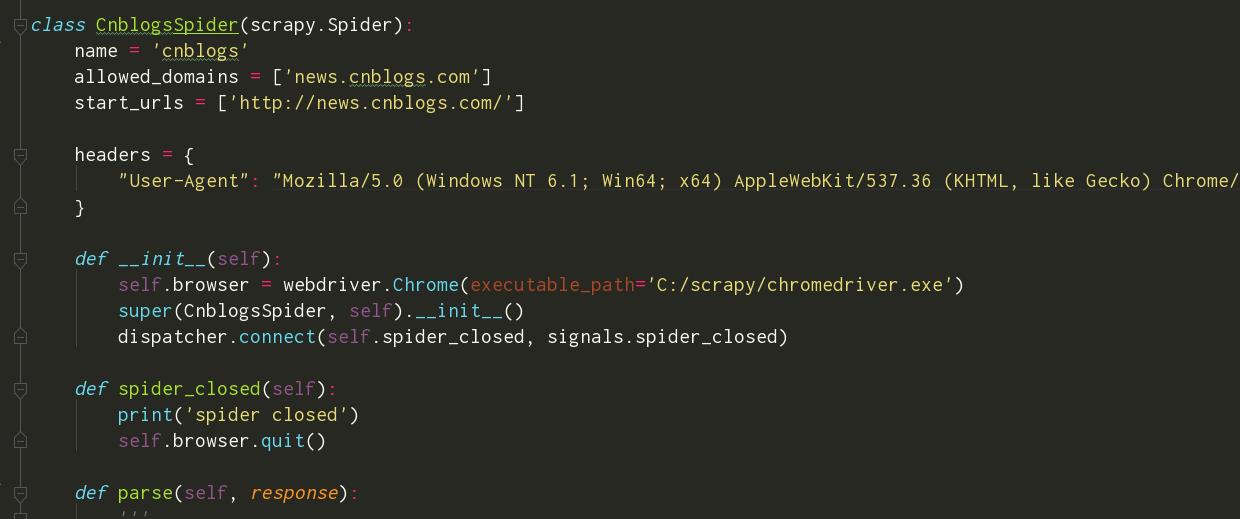

在imagepipeline 中解决吗?
写回答
1回答
-

bobby
2020-02-10
是所有的图片都下载失败 还是只有个别 这个url的图片 你有没有试过通过浏览器是否能打开?
032020-02-20
相似问题
将selenium集成到scrapy后,爬取cnblogs下载图片报错了。集成后怎么解决图片下载问题呢?
来源:9-4 selenium集成到scrapy中
楚人长铗
2020-02-09
在imagepipeline 中解决吗?
1回答

bobby
2020-02-10
是所有的图片都下载失败 还是只有个别 这个url的图片 你有没有试过通过浏览器是否能打开?
相似问题