crawlspider中能yield出去 Request的吗?
来源:9-10 scrapy的数据收集

WittChen
2020-02-15
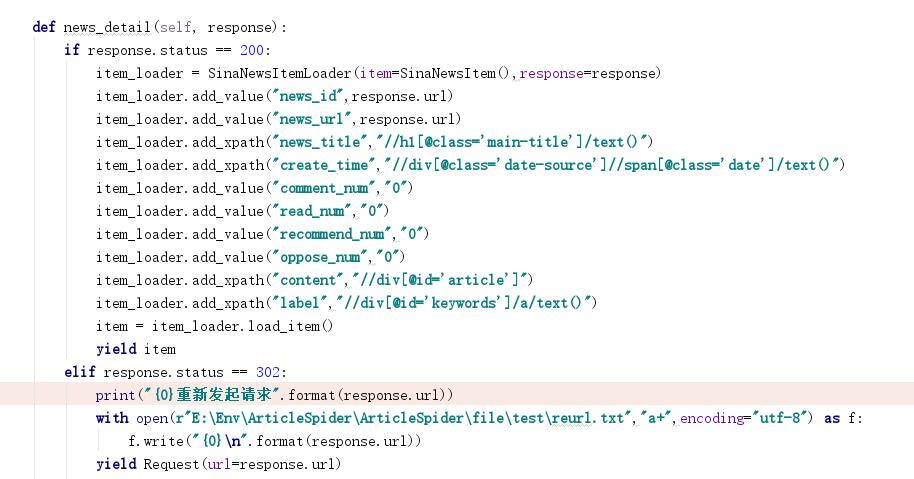
老师您好,如上图,我设置了status为302的url返回我再一次处理,按照道理只要这个url返回的状态是302的都会被处理,实施证明了也进入了这个函数,我把url写入了一个文件,我等到scrapy没有页面可爬的时候在elasticsearch中搜索这些url没发现写入数据,所以我就有疑问,我这样写对吗?
写回答
1回答
-
这样写其实看起来有道理,但是在某些情况下也可以说有点多余,为什么呢? 引起302可能会有3种情况:1. 某些url才会引起302,但是这些url并不是我们的目标url,比如未登录的时候,我们点击了一个需要登录才能访问的url,就好比“个人中心”,这个时候是会返回302的,但是这种url其实并不是我们关心的,因为我们使用了
crawlspider所以所有的url都会被跟进,但是我们自己写spider就不会去跟进这种url,这种就没有必要记录下来。 2. 某些url才会引起的302,并不是所有的url都会引起,这种情况下可以写入 3.当被反爬的时候,这个时候所有后续的url都可能会被302,这个时候并不是当前的url,对你来说更重要的可能是1.停止爬虫 2. 重新规划爬取速度 3. 模拟登录拿到cookie后续的所有的request才能继续抓取。 这个时候就没有必要记录下来,因为遇到这种问题你需要停下来想办法染过这个问题
032020-02-19

相似问题