博客园就爬取一条就停止了,连接es出了问题
来源:10-2 redis基础知识 - 1

fine纯粹
2020-04-02



我可以通过es_types来创建索引

那看来是数据导入es那里有问题
我是直接运行您的代码的
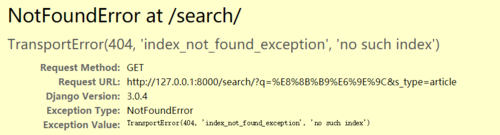
还有前端 TransportError(404, 'index_not_found_exception', 'no such index')
写回答
2回答
-

fine纯粹
提问者
2020-04-03
我是用您的源代码运行的,因为每页只爬取一条所以一下子就要登录了

博客园部分代码 不知道哪里出了问题,要怎么获取每页的全部文章呢?
#收集博客园所有404的url以及404页面数 handle_httpstatus_list = [404] def __init__(self, **kwargs): self.fail_urls = [] dispatcher.connect(self.handle_spider_closed, signals.spider_closed) def handle_spider_closed(self, spider, reason): self.crawler.stats.set_value("failed_urls", ",".join(self.fail_urls)) def parse(self, response): """ 1. 获取文章列表页中的文章url并交给scrapy下载后并进行解析 2. 获取下一页的url并交给scrapy进行下载, 下载完成后交给parse """ #解析列表页中的所有文章url并交给scrapy下载后并进行解析 if response.status == 404: self.fail_urls.append(response.url) self.crawler.stats.inc_value("failed_url") post_nodes = response.css('#news_list .news_block') for post_node in post_nodes: image_url = post_node.css('.entry_summary a img::attr(src)').extract_first("") if image_url.startswith("//"): image_url = "https:" + image_url post_url = post_node.css('h2 a::attr(href)').extract_first("") yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url}, callback=self.parse_detail) break #提取下一页并交给scrapy进行下载 next_url = response.xpath("//a[contains(text(), 'Next >')]/@href").extract_first("") if next_url: yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)00 -

bobby
2020-04-03
是否有运行es_model的init方法生成这个索引对象 你的es是什么版本?
042020-04-05


相似问题