启动scrapy crawl jobbole -s JOBDIR=job_info/001报错
来源:9-6 scrapy的暂停与重启

愚墨
2020-04-13

Unhandled error in Deferred:
2020-04-13 16:21:35 [twisted] CRITICAL: Unhandled error in Deferred:
2020-04-13 16:21:35 [twisted] CRITICAL:
Traceback (most recent call last):
File “H:\anaconda3.4\anaconda_\lib\site-packages\twisted\internet\task.py”, line 517, in oneWorkUnit
result = next(self.iterator)
File "H:\anaconda3.4\anaconda\lib\site-packages\scrapy\utils\defer.py", line 63, in
work = (callable(elem, *args, **named) for elem in iterable)
File "H:\anaconda3.4\anaconda\lib\site-packages\scrapy\core\scraper.py", line 183, in process_spidermw_output
self.crawler.engine.crawl(request=output, spider=spider)
File "H:\anaconda3.4\anaconda\lib\site-packages\scrapy\core\engine.py", line 210, in crawl
self.schedule(request, spider)
File “H:\anaconda3.4\anaconda_\lib\site-packages\scrapy\core\engine.py”, line 216, in schedule
if not self.slot.scheduler.enqueue_request(request):
File “H:\anaconda3.4\anaconda_\lib\site-packages\scrapy\core\scheduler.py”, line 57, in enqueue_request
dqok = self.dqpush(request)
File "H:\anaconda3.4\anaconda\lib\site-packages\scrapy\core\scheduler.py", line 86, in dqpush
self.dqs.push(reqd, -request.priority)
File "H:\anaconda3.4\anaconda\lib\site-packages\queuelib\pqueue.py", line 35, in push
q.push(obj) # this may fail (eg. serialization error)
File “H:\anaconda3.4\anaconda_\lib\site-packages\scrapy\squeues.py”, line 15, in push
s = serialize(obj)
File “H:\anaconda3.4\anaconda_\lib\site-packages\scrapy\squeues.py”, line 27, in pickle_serialize
return pickle.dumps(obj, protocol=2)
File "H:\anaconda3.4\anaconda\lib\site-packages\parsel\selector.py", line 204, in getstate
raise TypeError(“can’t pickle Selector objects”)
TypeError: can’t pickle Selector objects
2回答
-

bobby
2020-04-16
 你先试试不放这个进去会不会报错?022020-04-17
你先试试不放这个进去会不会报错?022020-04-17 -
bobby
2020-04-14
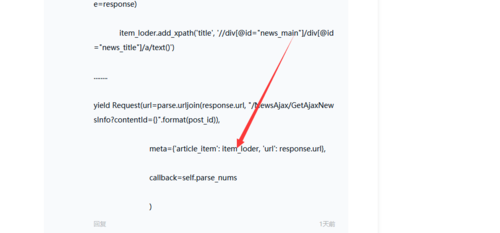
yield request对象的时候不能将selector对象放入到meta属性中,因为这个地方的值会进行pickle 这样会抛出异常 你可以将response的html放入进去 然后到另一个函数的时候在生成selector对象
022020-04-14

 你先试试不放这个进去会不会报错?
你先试试不放这个进去会不会报错?相似问题