crwalspider爬取url的问题
来源:7-3 CrawlSpider源码分析

慕娘7402538
2020-04-29
老师您好,在爬取拉钩网的时候还有很多页面的url不能被爬取到,这里我有两个问题:
第一个是https://www.lagou.com/gongsi地点的url他没有显示出来,放在了一个index中,我的想法是将这些url添加到start_urls中,但是太多了,不知道还有没有更好的办法。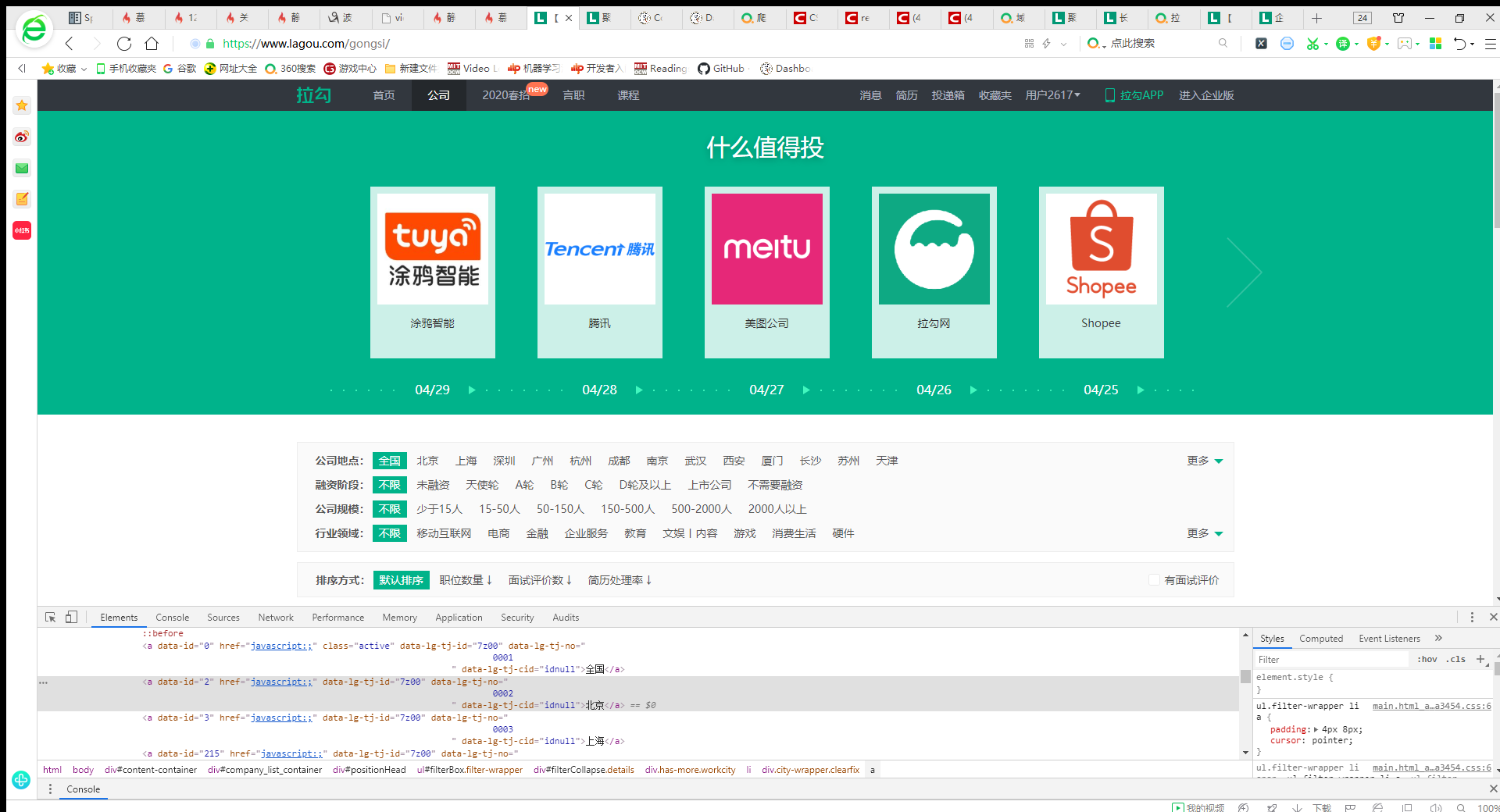
 第二个问题比较严重,就是他https://www.lagou.com/gongsi下方的页数标签不会返回url,也就是说所有页面只能爬取第一页的信息,
第二个问题比较严重,就是他https://www.lagou.com/gongsi下方的页数标签不会返回url,也就是说所有页面只能爬取第一页的信息,
点击第二页显示pager_is_current,url还是不变,就不知道怎么解决了。。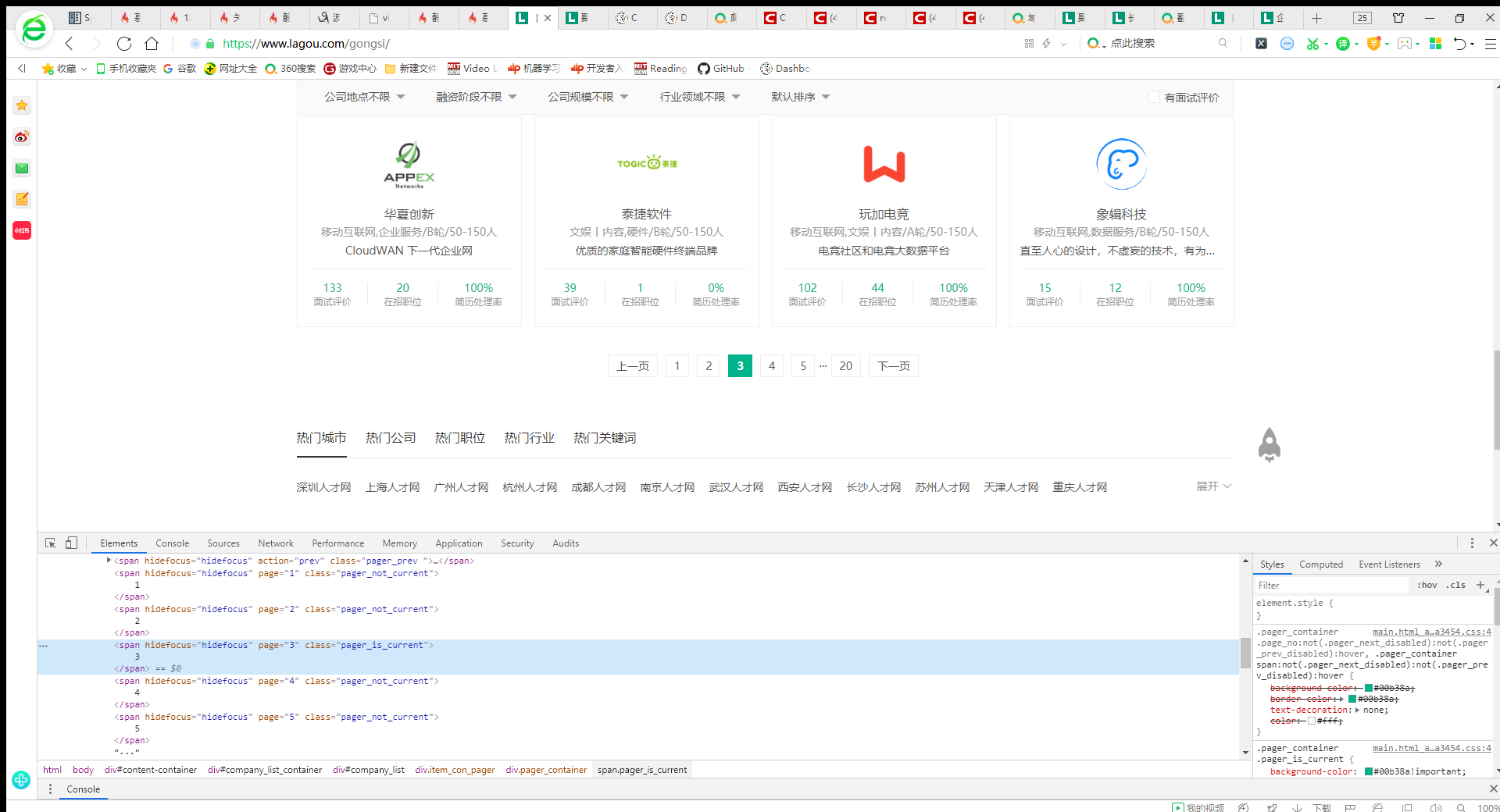
在首页如果要获取更多信息都会跳转到公司这个页面,就会有很多信息爬取不到。
写回答
1回答
-
课程中讲解过可以覆盖start_requests 这里面你可以抓取页面分析出来 然后for循环这个url就行了
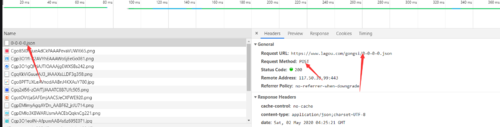
 通过网络请求就鞥分析出来这个请求是什么格式以及参数是什么
通过网络请求就鞥分析出来这个请求是什么格式以及参数是什么
032020-05-04


 通过网络请求就鞥分析出来这个请求是什么格式以及参数是什么
通过网络请求就鞥分析出来这个请求是什么格式以及参数是什么相似问题