知乎首页爬取出来的链接很少
来源:6-14 item loder方式提取question - 1

ciphermagic
2017-07-31
re.match("(.*zhihu.com/question/(\d+))(/|$).*", url)首页爬取出来的问题链接,只有三个。而且把response.text写入html中打开查看,网页不断刷新。是因为知乎的反爬虫策略么,目前有没有解决方案?
写回答
2回答
-
你需要截图 我看看 scrapy的log输入是什么
032017-08-02 -

ciphermagic
提问者
2017-08-01
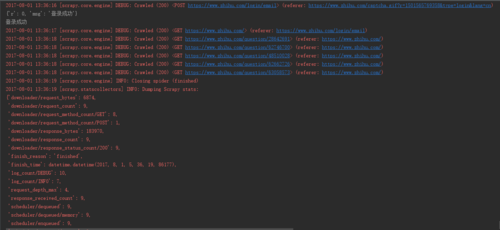
这次爬到五个问题链接,但不应该这么少啊
022017-08-01


相似问题