crawlspider模拟登陆拉钩问题
来源:7-4 Rule和LinkExtractor使用

慕圣1554054
2017-10-12
我用start_requests函数模拟登陆,获取到cookie后,怎么调用rule定义的需要爬取的url。我试了用start_urls里的url后就只能爬取到www.lagou的主页,并没有爬取到rules定义的zhaopin、jobs的一些页面。
写回答
3回答
-

精慕门5384516
2017-10-12
遇到同样的问题
112017-10-16 -

慕圣1554054
提问者
2017-10-17
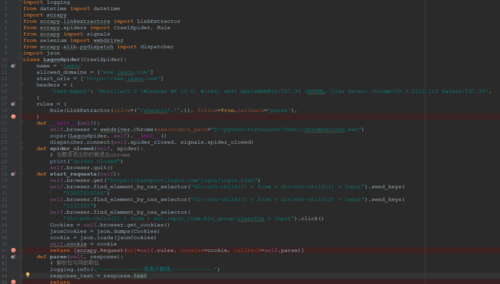 这个是我,代码032017-10-23
这个是我,代码032017-10-23 -

bobby
2017-10-16
亲你的解决了没有
012017-10-17

 这个是我,代码
这个是我,代码
相似问题