根据课程学习,当前项目遇到的问题和困难,真的希望老师帮我看看,谢谢老师
来源:6-17 知乎spider爬虫逻辑的实现以及answer的提取 - 1

daixu_35
2023-11-29
老师,您的课程是我爬虫的领路人,课程确实让我学到了很多。不过现在我们的反爬策略确实不适用当前zhihu了。在我力所能及及的范围内(一个非计算机专业的大学生),我提几个点吧:
1. 滑动验证码
当前的滑动验证码输入账号密码后,出来的背景图片和滑块的html标签,在网页中,如果直接xpath根据属性名定为它,即使是从它较前的父元素定位下来,会被导向一个莫名的本机端口一直循环,出不来,原因大概是,在直接搜索那个属性名的时候,会同时定位出一段奇怪的css文本在网页中,这我确实不太懂什么原理,前端的开发我虽有项目,但也是较为简单的项目,还不太理解。(图1)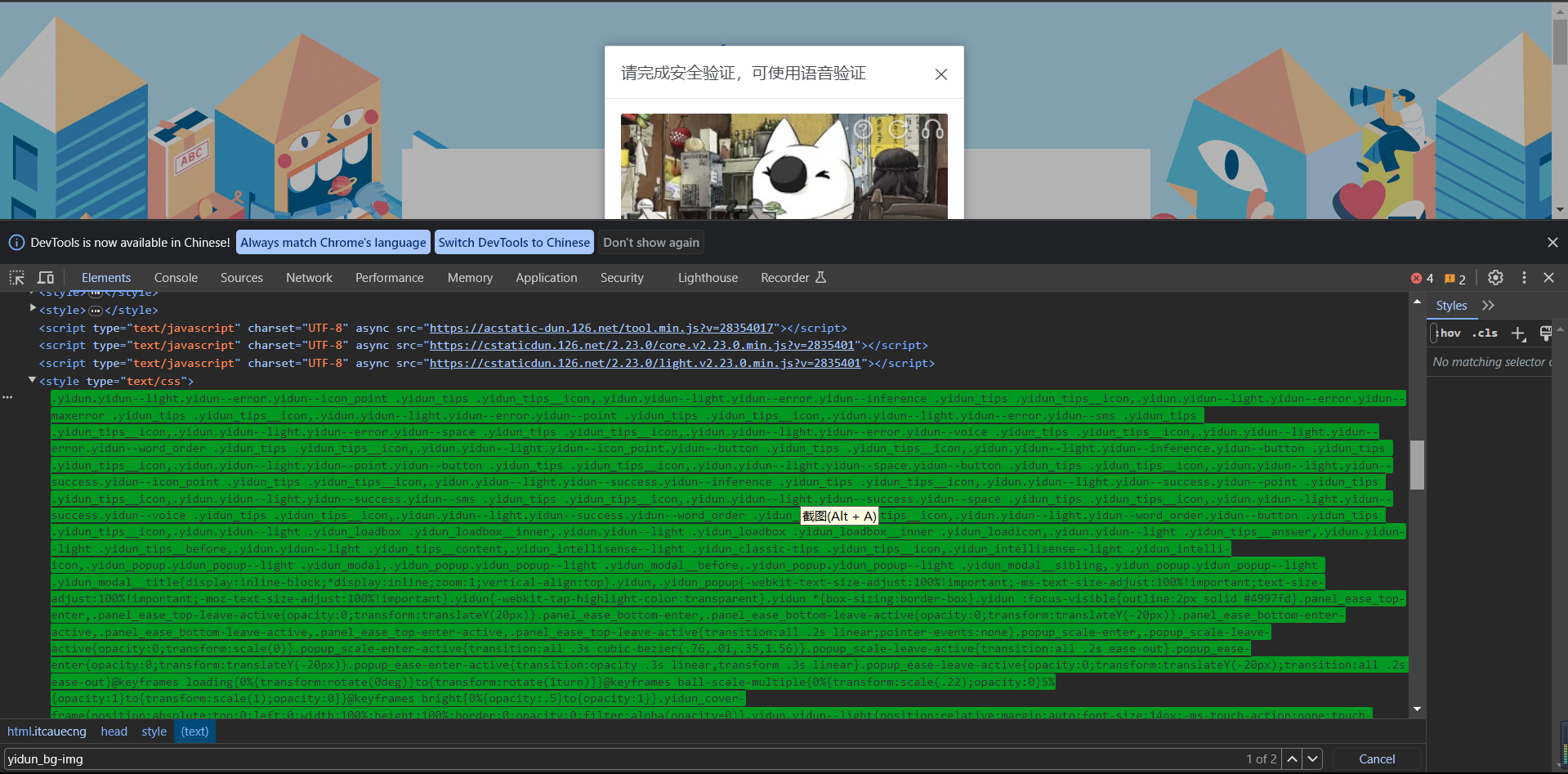
不过这个问题我自己尝试了一下,用最笨的直接浏览器自带的copy xpath这样的一层一层定位的笨方法反而能定位获取成功。此外,opencv的识别方法,老师的源码我也拜读理解了,同时复用以后,现在的验证码图像相比以前,使用opencv进行模板匹配还是勉强了,即使我加上了轮廓计算等opencv的处理,依然还是不尽人意,所以最后使用了百度EasyDL的接口来做了。
2. 问题项url解析
登录完毕进入主页后,拥有很多问题项,而我们需要提取它们的进入url,这里有一个很神奇的现象,由于问题项是动态网页请求的,所以我分析了网页的ajax请求,找到了其中的ajax请求包,但当我单独拿出这个url,直接放网址请求时,得到的结果和网页上的根本不一样!我一开始也很吃惊,多番对比后确认了确实是这样的。(图2)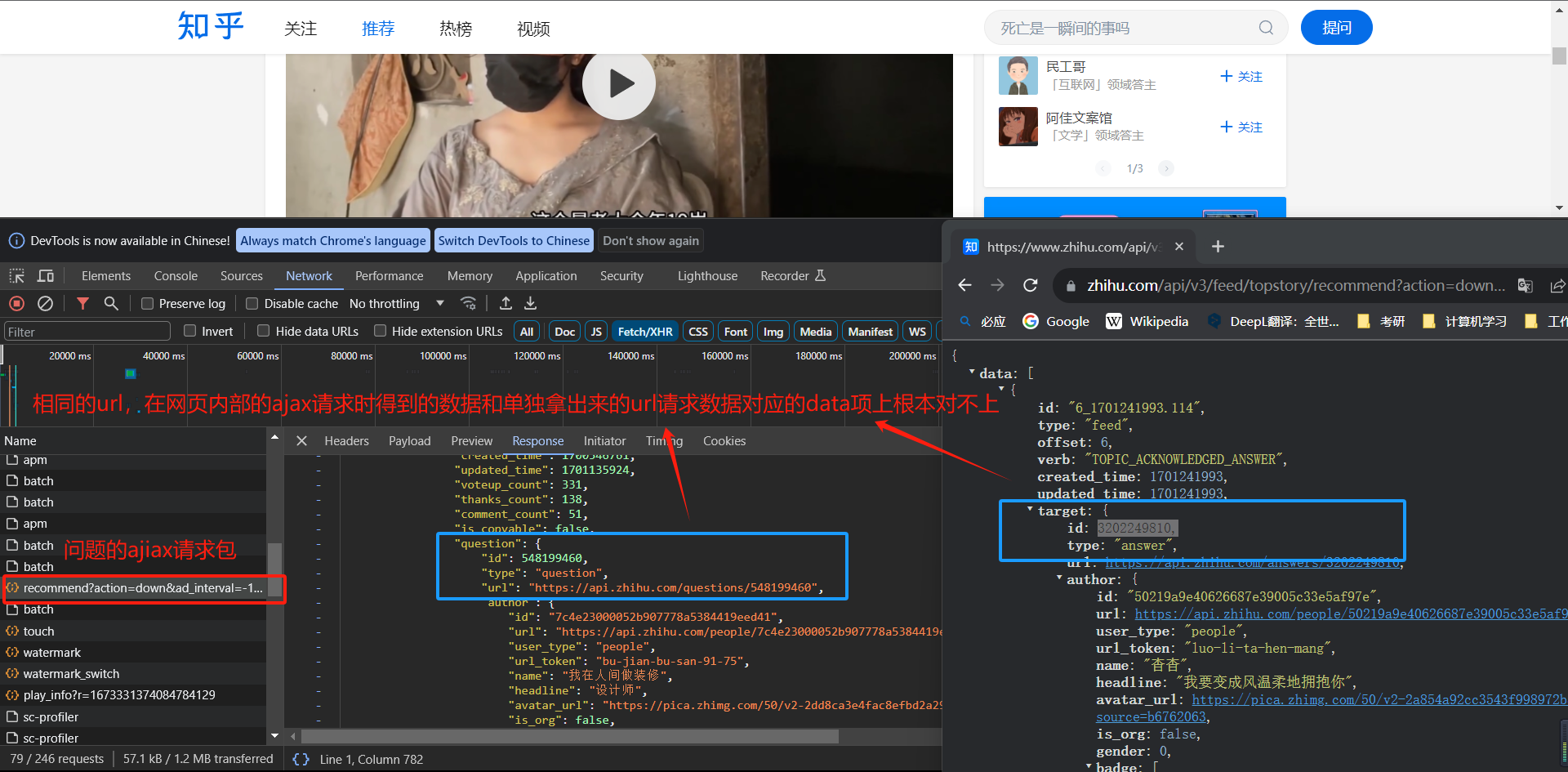
这个我也实在分析不出来是什么原因,我最后采用在downloader middleware里设置针对主页时使用selenium滚动窗口加载较多的问题项后,再返回回去spider解析问题项的url,同时注意到每次进入知乎首页时,问题项的加载都是随机的,并不是按照发布时间排列,所以在爬取问题项url的同时,又将首页url给yield出去再获取新的。
3. 回答项解析
回答页面在之前的课程中讲解时,我们是通过直接进入https://www.zhihu.com/question/333711492
这样的url,然后分析出加载回答项的ajax请求url结构,然后直接请求拿到结果从json中得到数据,而我们需要得到那个初始的ajax请求,然后根据它json中的next url向后遍历。在课程讲解的那个时候,这个ajax的url主要是offset与limit有控制,但是现在的这个url中和以前已经不一样了!具体如下:(这是我摘取的两个例子url,中间无关的参数我已经自动删除了,否则太长了)
第一个:
https://www.zhihu.com/api/v4/questions/333711492/feeds?cursor=375369c75aa568e3ae21b1bb922f502f&limit=5&offset=0&order=default&platform=desktop&session_id=1701244572319969425
第二个:
https://www.zhihu.com/api/v4/questions/333711492/feeds?cursor=375369c75aa568e3beba178e922f502f&limit=5&offset=0&order=default&platform=desktop&session_id=1701244572319969425
这是对同一个问题连着的两个新加载的ajax请求,它们的offset和limit我在测试中,一直都毫无作用,而关键的是这个cursor值,只有它是决定性的,它决定了返回的内容的完整性和不同的回答。但这个cursor应该是某种加密了吧,我暂时的能力确实是分析不出来。。。
那么没法获得起始的cursor值,就别说去获得下一个了。我自己想那就在回答页面截获这第一个ajax请求就行,分析后发现,如果直接访问
url:https://www.zhihu.com/question/620099680这个页面,是不会加载第这第一个ajax请求的,而如果访问url:https://www.zhihu.com/question/620099680/answer/3238107073是有起始的这个需要的ajax请求的,也就是需要访问带answer后缀的这个url(图3)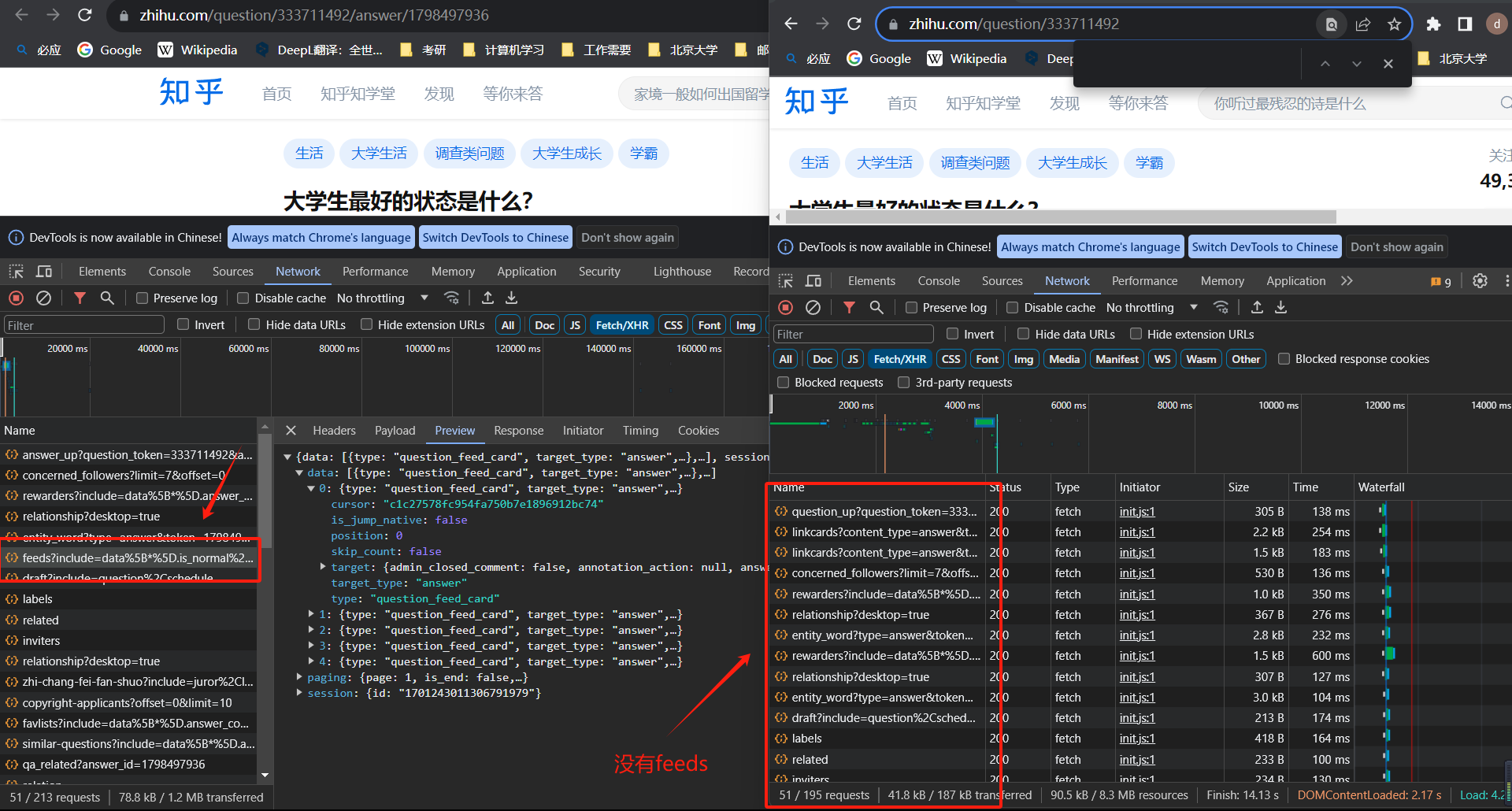
所以,我采用策略,使用selenium去加载这个url,并截获这个页面同时发起的所有其他请求,从中过滤出这个带feeds的url,这个过程中,我使用了browsermob-proxy库,搜索资料时,似乎它是这个需求很常用的方法,但接下来这个问题我不会解决了。在我配置好browsermob-proxy后,一开始时非常顺利的,它确实截获下来了,我也收到了,但是在我仅仅用了几次以后,只要我加上browsermob-proxy,就直接被知乎识别为机器人并弹出很麻烦的验证码,根本没法继续,而只要我一去掉browsermob-proxy服务,就能进入页面,以下是我的简单测试代码和一些截图:
from browsermobproxy import Server
import time
import undetected_chromedriver as uc
from selenium.webdriver.chrome.options import Options
# 启动代理
server = Server("E:\project\ZhuhuSpider\\browsermob-proxy-2.1.4\\bin\\browsermob-proxy.bat")
server.start()
proxy = server.create_proxy()
print('proxy', proxy.proxy)
# 启动浏览器
chrome_options = Options()
# chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))
driver = uc.Chrome(options=chrome_options)
# 监听结果
base_url = 'https://www.zhihu.com/question/424639165/answer/3183777242'
proxy.new_har(options={
# 'captureContent': True,
'captureHeaders': True
})
driver.get(base_url)
time.sleep(3)
# 读取结果
result = proxy.har
for entry in result['log']['entries']:
print(entry['request']['url'])
print(entry['response']['content'])
driver.close()
proxy.close()
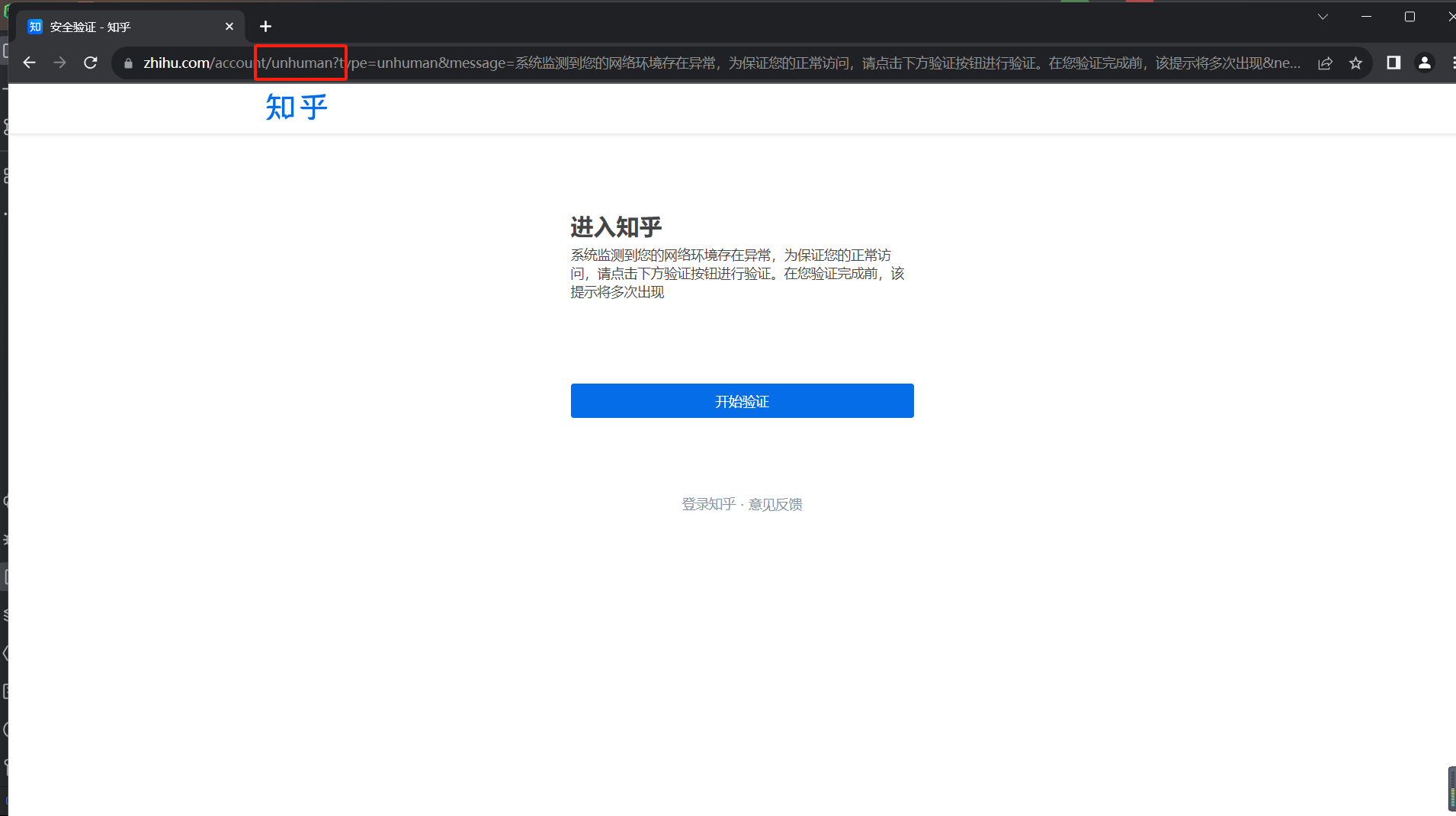
我查阅了很多资料,都没法完全解决这个问题,每次换一个方法使用几次后,都会被识别为机器人,但是一旦我去掉chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy)),或者直接不用browsermob-proxy就可以进入知乎,所以,我觉得问题肯定是处在browsermob-proxy上,我没法解决了。想请求老师帮帮看看吧。
1回答
-
 这是我这里定位的,没有出现你说的问题啊
这是我这里定位的,没有出现你说的问题啊推荐页同一个url每次进去内容不一样是正常的啊,产品就是这样设计的
cursor可以参考这篇 https://www.cnblogs.com/SfishEgg/articles/16945614.html
proxy-server能被识别出来 应该是js中执行一些检查 识别出来了一些参数 可以不设置这些参数就行了
022023-12-02

相似问题