Pipline调试数据疑问
来源:4-15 items的定义和使用 - 2

beloved1234
2023-12-13
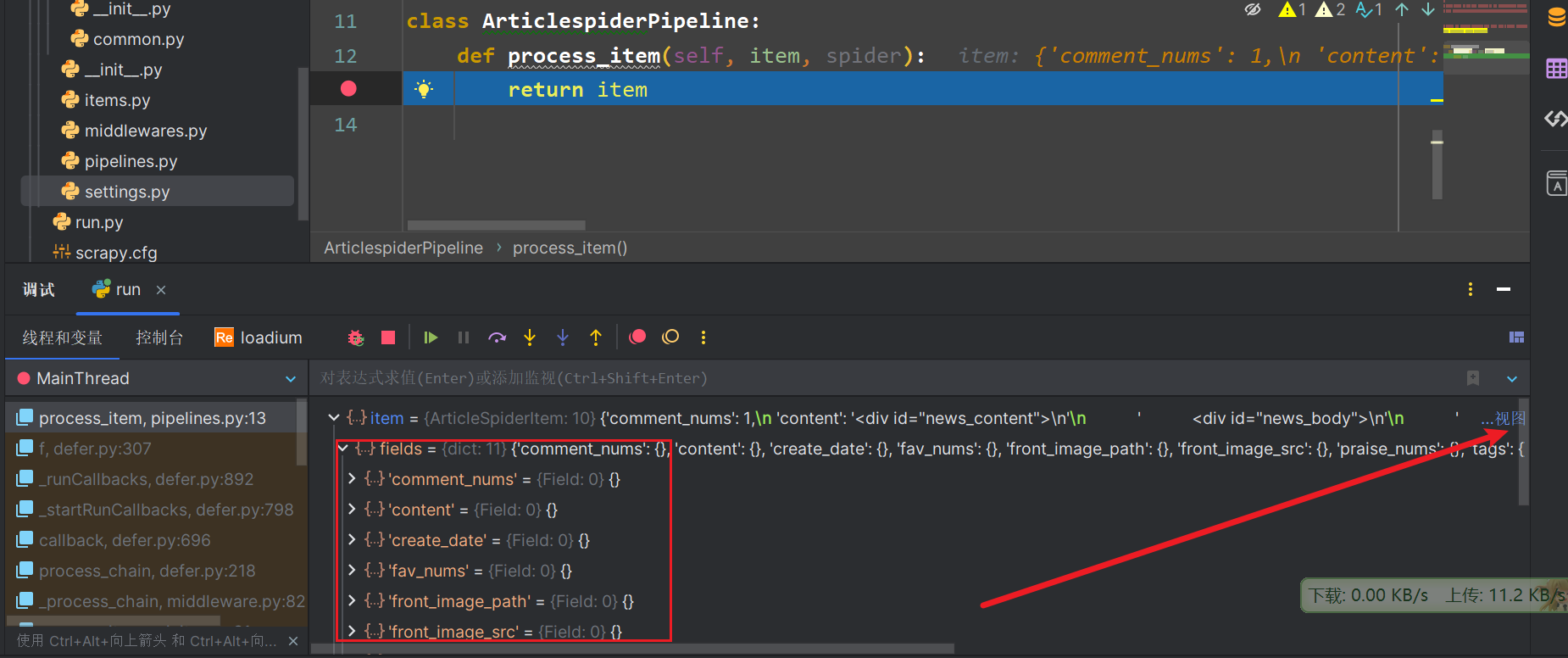
在调试pipline时,item有值,箭头哪里,但是 下面却没有值,这是怎么回事啊
写回答
1回答
-

beloved1234
提问者
2023-12-13
而且整个项目中只有一个 yield item
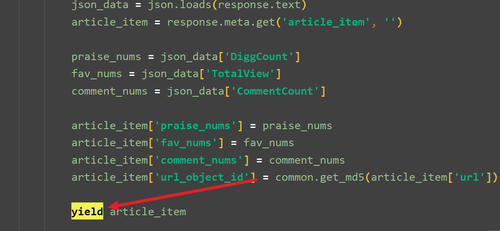
import re import json import scrapy from fake_useragent import UserAgent from urllib import parse from scrapy import Request from selenium import webdriver from ArticleSpider.items import ArticleSpiderItem from ArticleSpider.utils import common class BlogparkSpider(scrapy.Spider): name = "BlogPark" allowed_domains = ["news.cnblogs.com"] start_urls = ["https://news.cnblogs.com"] def parse(self, response, **kwargs): post_nodes = response.css('#news_list .news_block') for post_node in post_nodes: # 图片 image_src = post_node.css('div.entry_summary a img::attr(' 'src)').extract_first('') # 文章地址 chapter_url = post_node.css('h2 a::attr(href)').extract_first('') yield Request( parse.urljoin(response.url, chapter_url), meta={ 'front_image_url': image_src }, callback = self.details ) def details(self, response): pattern = re.match(r'.*?(\d+)', response.url) if pattern: post_id = pattern.group(1) article_item = ArticleSpiderItem() # 文章标题 title = response.css("#news_title a::text").extract_first('') # 发布时间 create_date = response.css('#news_info span.time::text').extract_first('') date_pattern = re.match(r'.*?(\d+.*)', create_date) if date_pattern: create_date = date_pattern.group(1) # 文章内容 content = response.css('#news_content').extract()[0] # 标签 tag_list = response.css('div.news_tags a::text').extract_first('') tags = ','.join(tag_list) # 给 article_item 赋值 article_item['title'] = title article_item['create_date'] = create_date article_item['content'] = content article_item['tags'] = tags article_item['front_image_src'] = response.meta.get( 'front_image_src', "") article_item['title'] = title article_item['url'] = response.url yield Request( parse.urljoin(response.url, f"/NewsAjax/GetAjaxNewsInfo?contentId=" f"{post_id}"), meta={ 'article_item': article_item }, callback=self.parse_nums ) def parse_nums(self, response): json_data = json.loads(response.text) article_item = response.meta.get('article_item', '') praise_nums = json_data['DiggCount'] fav_nums = json_data['TotalView'] comment_nums = json_data['CommentCount'] article_item['praise_nums'] = praise_nums article_item['fav_nums'] = fav_nums article_item['comment_nums'] = comment_nums article_item['url_object_id'] = common.get_md5(article_item['url']) yield article_item012023-12-18
相似问题