获取到的response,用response.css方法失效,可是已经模拟登录了
来源:1-1 python分布式爬虫打造搜索引擎简介

慕慕1544801
2024-04-11
图为response的text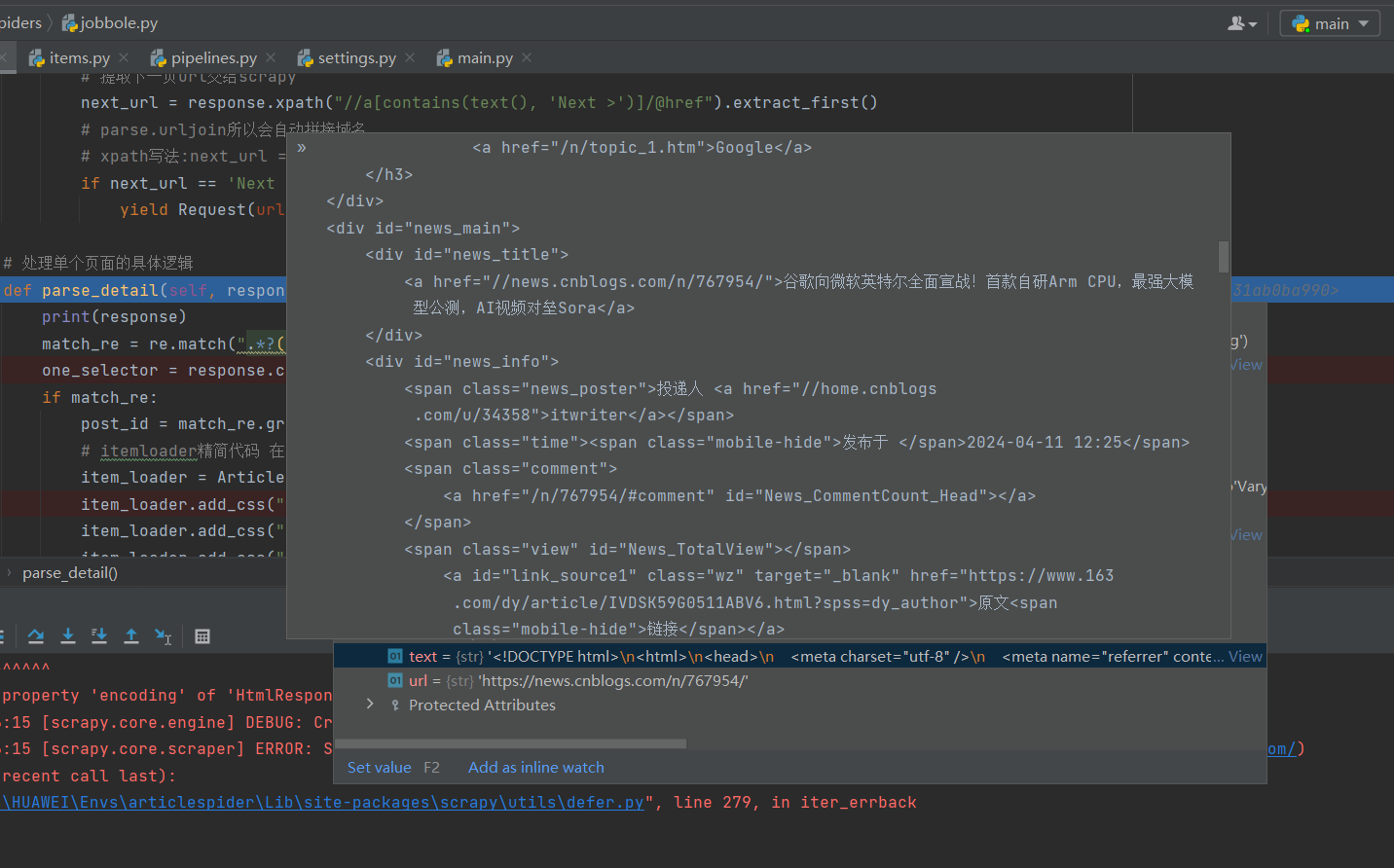
检看response.css时发现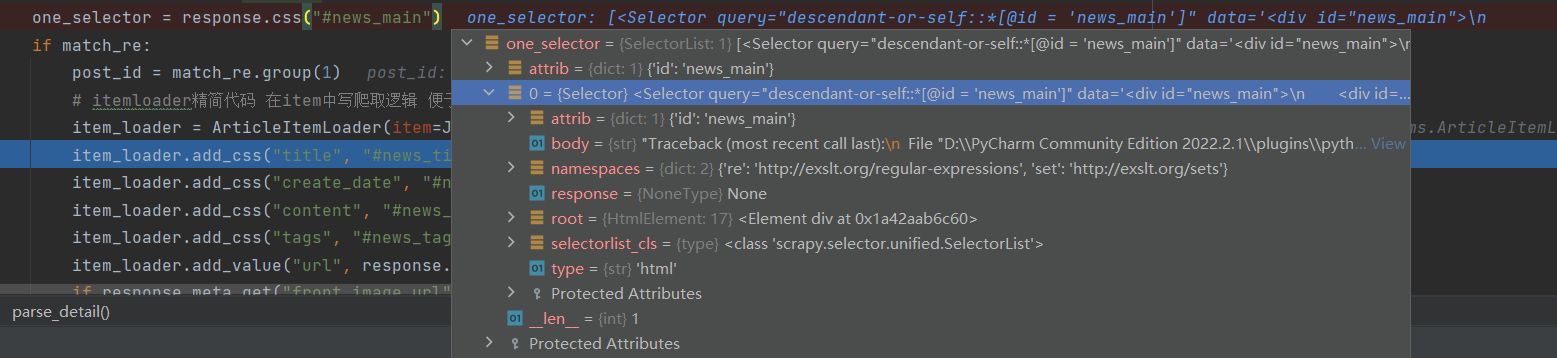
但是控制台却没有报错啊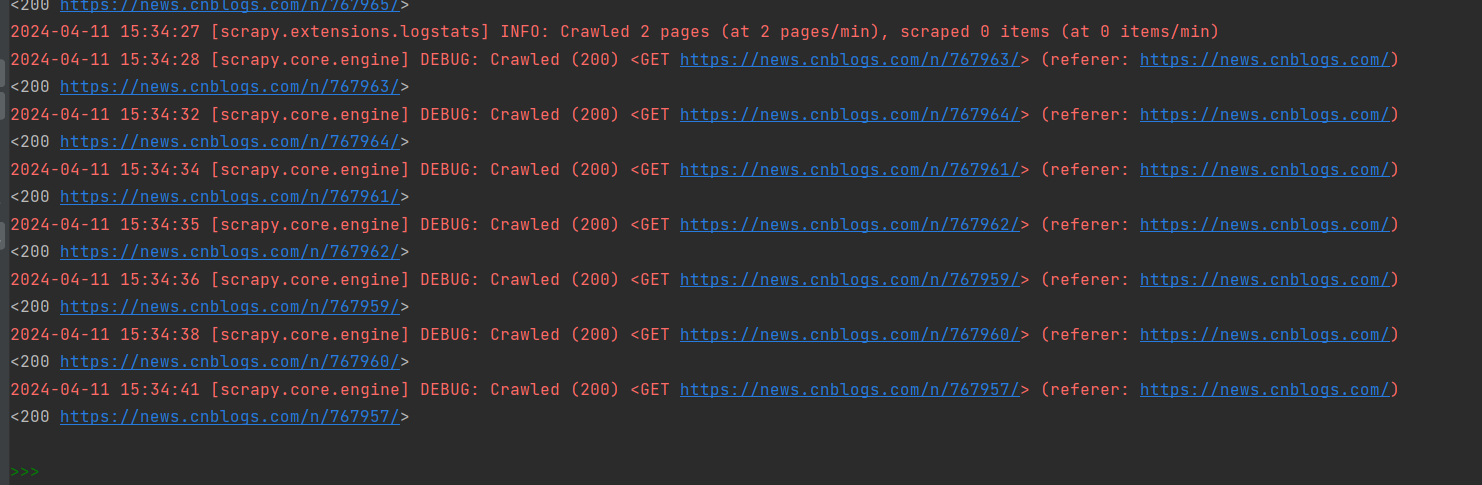
后来按老师的代码写
我发现itemloader里的item是空的 但是response又是200状态码并且获取成功页面 我调试发现如下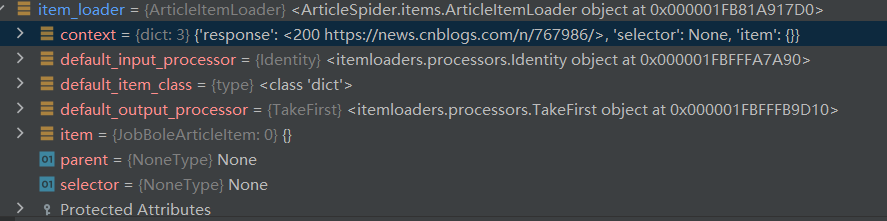
控制台报错
To use XPath or CSS selectors, ArticleItemLoader must be instantiated with a selector
写回答
3回答
-

慕慕1544801
提问者
2024-04-12
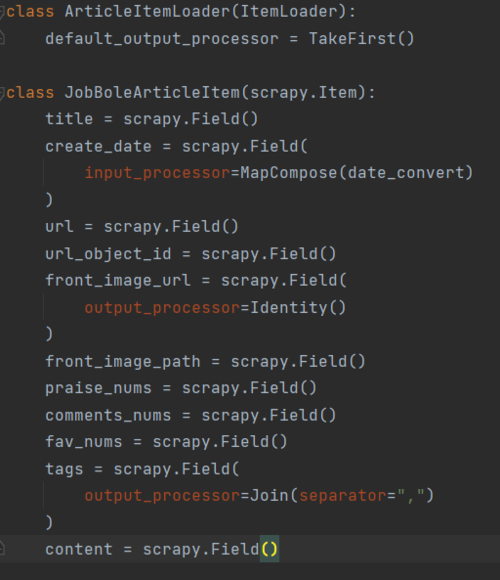 就是这个啦022024-04-12
就是这个啦022024-04-12 -
慕慕1544801
提问者
2024-04-12
Traceback (most recent call last): File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\utils\defer.py", line 279, in iter_errback yield next(it) ^^^^^^^^ File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\utils\python.py", line 350, in __next__ return next(self.data) ^^^^^^^^^^^^^^^ File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\utils\python.py", line 350, in __next__ return next(self.data) ^^^^^^^^^^^^^^^ File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\core\spidermw.py", line 106, in process_sync for r in iterable: File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\spidermiddlewares\offsite.py", line 28, in <genexpr> return (r for r in result or () if self._filter(r, spider)) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\core\spidermw.py", line 106, in process_sync for r in iterable: File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\spidermiddlewares\referer.py", line 352, in <genexpr> return (self._set_referer(r, response) for r in result or ()) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\core\spidermw.py", line 106, in process_sync for r in iterable: File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\spidermiddlewares\urllength.py", line 27, in <genexpr> return (r for r in result or () if self._filter(r, spider)) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\core\spidermw.py", line 106, in process_sync for r in iterable: File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\spidermiddlewares\depth.py", line 31, in <genexpr> return (r for r in result or () if self._filter(r, response, spider)) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\scrapy\core\spidermw.py", line 106, in process_sync for r in iterable: File "C:\Users\HUAWEI\ArticleSpider\ArticleSpider\spiders\jobbole.py", line 95, in parse_detail item_loader.add_css("title", "#news_title a::text") File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\itemloaders\__init__.py", line 407, in add_css values = self._get_cssvalues(css) ^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\itemloaders\__init__.py", line 441, in _get_cssvalues self._check_selector_method() File "C:\Users\HUAWEI\Envs\articlespider\Lib\site-packages\itemloaders\__init__.py", line 326, in _check_selector_method raise RuntimeError( RuntimeError: To use XPath or CSS selectors, ArticleItemLoader must be instantiated with a selector 2024-04-12 10:34:34 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://news.cnblogs.com/n/768003/> (referer: https://news.cnblogs.com/)代码
def parse_detail(self, response): #print(response.text) match_re = re.match(".*?(\d+)", response.url) #one_selector = response.css("#news_main") #print(one_selector.extract()) if match_re: post_id = match_re.group(1) # item loader精简代码 在item中写匹配存储逻辑 便于后期增加并且重用性好 item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response) item_loader.add_css("title", "#news_title a::text") item_loader.add_css("create_date", "#news_info .time::text") item_loader.add_css("content", "#news_content") item_loader.add_css("tags", "#news_tags a::text") item_loader.add_value("url", response.url) if response.meta.get("front_image_url", []): item_loader.add_value("front_image_url", [response.meta.get("front_image_url", [])]) # 异步方式实现 最好用异步方式符合SCRAPY框架 #print(item_loader.item) yield Request(url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)), meta={"article_item": item_loader, "url": response.url}, callback=self.parse_nums) pass022024-04-12 -

bobby
2024-04-12
To use XPath or CSS selectors, ArticleItemLoader must be instantiated with a selector 这个提示的地方截图我看看完整的错误战 以及你的这里的代码截图我看看呢
062024-04-24

相似问题