关于对随机种子对KNN分类器准确率的影响
来源:4-5 超参数

NTeam6
2020-07-03
老师您好,在写论文的时候用KNN算法,结论里需要给出一个预测的准确率。但其实在数据归一化、超参数网格搜索都完成之前,train_test_split时的随机种子对最后的准确率也是有影响的。
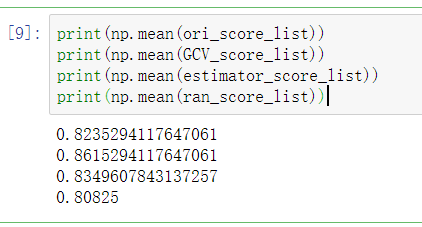
我编写程序,在完成数据归一化和超参数的网格搜索之外,对随机种子进行了从0到999的搜索,发现当随机种子取799时,预测准确率最低为,62.7%,当随机种子取910时,预测准确率最高,为96.1%。
那这个时候到底该怎么评价这个KNN分类器的准确度?
我尝试取1000个随机种子准确率的平均值:83.5%,但是此准确率是没有对应的K值和p值的,因为随机种子不同,网格搜索得到的最佳K值和p值也不同。
另外我对您讲课时用的鸢尾花数据集也在0到99间对随机种子进行了搜索,发现最高100%,最低86.8%,对应的随机种子分别是63和74。相差还是挺大的。

写回答
1回答
-

liuyubobobo
2020-07-03
不应该对种子做搜索。
这个问题是这样的,划分成的测试数据集,相当于在模拟完全不知道的,没有见过的数据。所以,在划分一次以后,测试数据只能扔到一边。完全靠训练数据集得到模型,测试数据集的作用是报告结果。测试数据及不是调试模型使用的。
你的做法等同于在拟合测试数据集,关于拟合测试数据集,在课程讲交叉验证的时候会说明。
所以,正规的数据集,都直接定义好了什么是训练数据集,什么是测试数据集,比如课程中后续实验的 MNIST 数据集。可以参考这个问答:http://coding.imooc.com/learn/questiondetail/75480.html
继续加油!:)
00

相似问题