scala建表,hive查询为空
来源:7-6 -操作Hive表数据

侧耳倾听17
2020-06-18
老师您好,我用scala命令spark.sql(“select pday,count(*) num from xtbl group by pday order by pday”).write.saveAsTable(“test1”)新建了一张test1表。之后用scala命令spark.table(“test1”).show()和sparksql都可以查到插入的数据内容。但是在hive里select查询出结果为空。
3回答
-

侧耳倾听17
提问者
2020-06-18
老师您好,我用spark-shell --master local[2] --jars /home/hadoop/software/mysql-connector-java-5.1.27-bin.jar启动scala,然后输入spark.sql("select pday,count(*) num from xtbl group by pday order by pday").write.saveAsTable("test1")
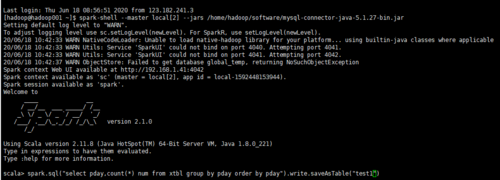
输入spark.table("test1").show()可以看到查询结果
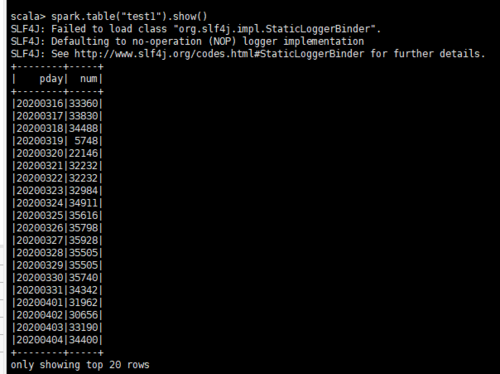
用spark-sql --master local[2] --jars /home/hadoop/software/mysql-connector-java-5.1.27-bin.jar启动sparksql输入select * from test1可以看到查询结果
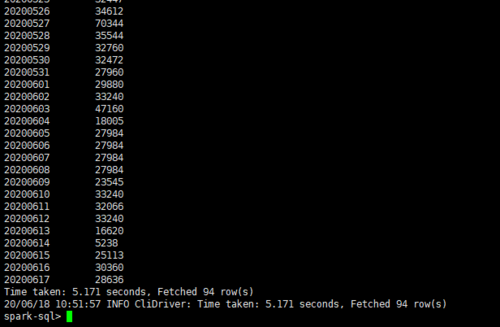
启动hive,desc test1可以看到表结构

在hive中输入select * from test1查询结果为空

HDFS中文件格式是.snappy.parquet
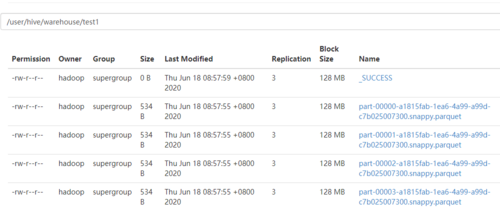 00
00 -
侧耳倾听17
提问者
2020-06-18
老师您好,之前安装spark时从hive拷贝了hive-site.xml文件,之前在hive里建表用scala和sparksql可查询出结果。scala里面没有做任何配置,是否要包mysql的jar包考入scala的lib文件夹。
012020-06-18 -

Michael_PK
2020-06-18
你的spark和hive使用的是同一套元数据吗?问题肯定出在这里
022020-06-18







相似问题