jar包冲突问题
来源:1-20 -YARN环境搭建及提交作业到YARN上运行

mitocainiao
2017-08-08

老师,我没有用cdh那个版本,每次运行spark都会在datanode的机器里的tmp目录下生成一些jar包 导致冲突,该怎么解决呢
写回答
4回答
-

mitocainiao
提问者
2017-08-08
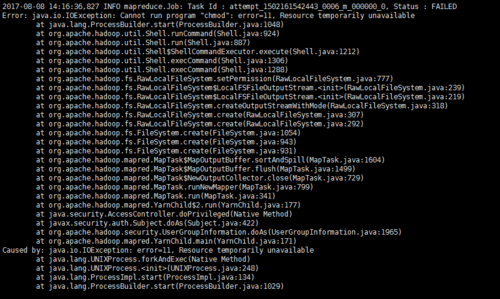
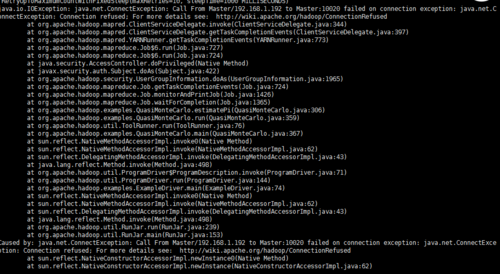
测试yarn结果


 00
00 -

Michael_PK
2017-08-08
你先确保你的yarn能正常运行作业不,你可以提交一个mr的pi上去测试下
012017-08-08 -
mitocainiao
提问者
2017-08-08
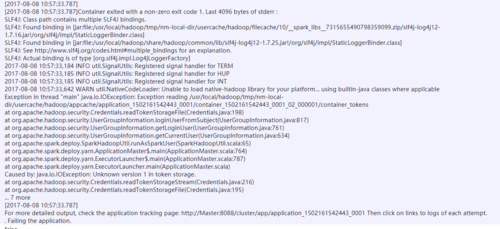
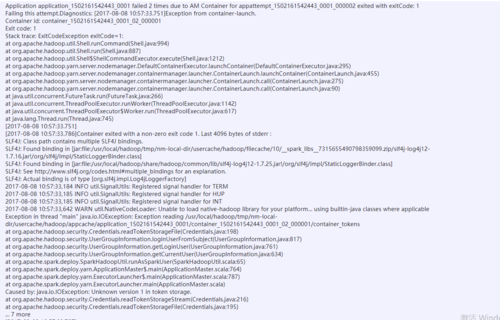
这个任务执行失败了
 00
00 -
Michael_PK
2017-08-08
你这截图不是问题,影响最终结果吗
022017-08-08







相似问题