zeppelin启动问题
来源:9-23 -使用Zeppelin进行统计结果的展示

mitocainiao
2017-08-09

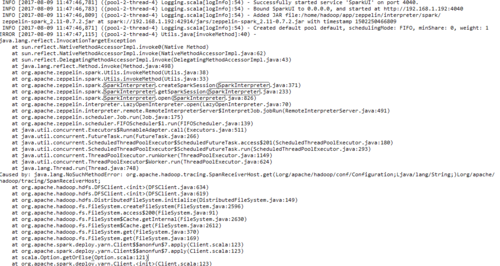
一旦我在spark-env.sh或者是zeppelin-env.sh中加入HADOOP_CONF_DIR,zeppelin就没有办法运行,会报错,把HADOOP_CONF_DIR
注释掉又好了,我想在zeppelin里面使用yarn模式啊,不加HADOOP_CONF_DIR没法用


写回答
3回答
-

Michael_PK
2017-08-09
你的hadoop是我们上课的版本?
012017-08-09 -

mitocainiao
提问者
2017-08-09
、
使用yarn-client模式
 00
00 -
Michael_PK
2017-08-09
export写没,不应该你说的那样,看看日志信息
022017-08-09


相似问题