主成分分析
来源:7-4 求数据的前n个主成分

黄义舜
2022-08-21
波波老师这章有些定义不明白
- 求出第一个主成分之后,如何求出下一个主成分?
对于这句话,求第一主成分,我理解的是,将一个平面中的点通过降维(方差最大,也就是更能体现数据间的差异)的方式放到一个向量上。从二维到一维
但对于求出下一主成分,我这个理解不了。是将数据从三维或者更高,映射到二维或者更高的维度吗
- 数据进行改变,将数据第一个主成分上的分量去掉
这一句也听不明白,
1.我不知道分量代表的是什么
2.我不明白为什么求下一个主成分需要将第一个主成分的分量去掉
1回答
-
PCA 确实理解起来稍微有些复杂,因为相对比较抽象,且是我的这个课程覆盖的范围里,最“数学”的部分(虽然求解 PCA 的过程,我已经更换成了非数学的方法。)
我在课程中介绍的一个“失误”,是主要以二维平面为例子让大家理解 PCA。这确实有难度。因为对于二维平面来说,找到第一个主成分以后,就剩一个主成分需要找了,而剩下的这一个主成分的寻找,其实某种程度上讲,已经和我们的数据无关了,剩下的这一个主成分,只要和我们的第一个主成分垂直就 ok 了。我觉得你的问题主要聚焦在这里,所以你的问题其实非常自然。
下面,我将尝试用三维数据来解释一下你的问题。非常麻烦的是,用三维数据来解释这个问题,是我们用图像的方式去“直观地”,“可视化地”理解这个算法的“最后机会”了。因为我们无法可视化四维或者更高维度的数据了。我们只能“抽象地”把我们的理解,去拓展到更高维度。但是,我觉得三维应该已经够了。
(我非常喜欢你表达问题的方式,表达得非常清晰。所以如果看了下面的解释,你还有问题的话,可以随时追加提问。)
==========
首先,非常重要的一个对 PCA 的整体认识是:PCA 求解的是一个新的空间(的基)。
为什么要求解一个新的空间?为了降维。
为什么求解一个新的空间就可以降维?这一点在这一章开始有一个二维例子的解释。我个人认为这个二维的例子就够说明这个问题了:
以这个数据为例:
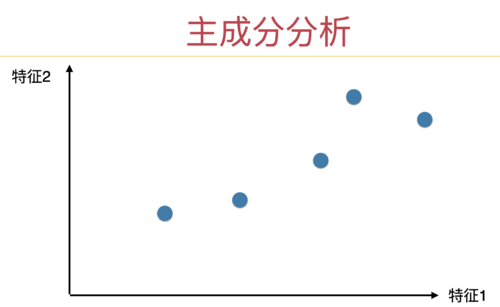
最直观的降维方法是:或者直接扔掉特征 1,只剩下特征 2,就降维了;
或者直接扔掉特征 2,只剩下特征 1,也降维了。
这几页 ppt 在描述这两种降维方式:
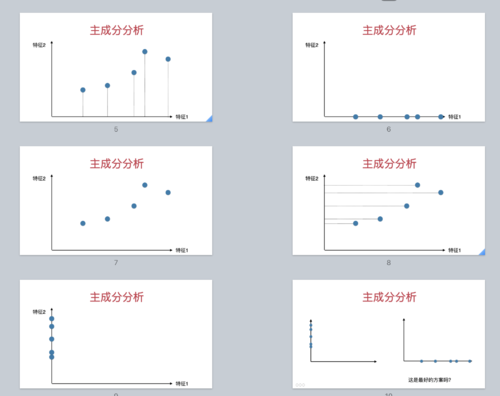
但是,这种降维方式,不是最好的。最好的方式是什么?对于这个数据,如果我们把数据映射到这样一个一维空间(一维直线上),损失的信息最少。
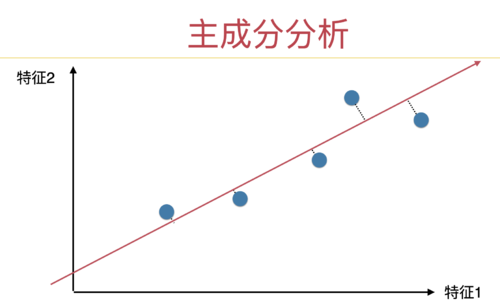
至于什么叫“损失的信息最少”,就是课程中介绍的:保留的方差最大。你的问题中对这一点没有疑问,所以我就不展开了。本质就是定义一个式子,然后求解这个式子,求解的结果就是这个轴。也就是一个主成分。
下面这一页 PPT 阐述了,在 PCA 下,求解出的这个轴是什么样子的。(和上面的图最大的区别是,数据经过了 demean,使得求出的轴也过原点了。)

因为对于二维数据来说,我们降维,也就降到一维。所以,课程中,对于二维的例子,到这里就结束了。
但是,实际上,运行课程后续介绍的完整的主成分分析的算法,我们还将得到第二个轴。是这个样子的:
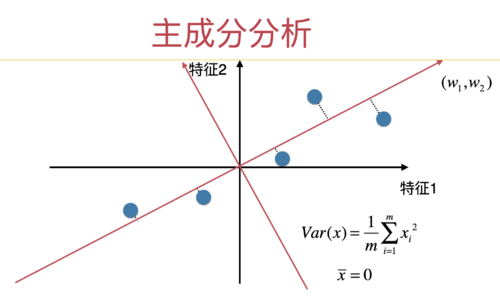
这是对二维数据做主成分分析,得到的完整结果。我们得到了一个新的二维空间的基(红色的轴)。
现在,我们所有的数据点,就可以从用黑色的轴所代表的空间,映射到红色的轴所代表的空间。
现在,数据点在红色的轴所代表的空间,在第一个轴中,保留的信息最多;在第二个轴,保留的信息次多。
此时,如果我们要降维的话,我们可以扔掉红色的轴中的第二个轴的所有信息,只保留红色的轴第一个轴上的所有信息。
这其实就是在课程初始我介绍的最 naive 最简单的降维方式!只不过,直接在原始的坐标轴上这样降维,损失的信息很多。PCA 做的事情,就是求出了一套新的坐标轴,在新的坐标轴上,数据在每个轴上的信息含量是逐渐递减的。这样,我们就可以扔掉“靠后”的坐标轴上的信息,完成降维。
===========
有了这个概念,我们看如何求第二个主成分。
我们还是先从二维看。在二维空间中,当我们求出第一个主成分(也就是第一个轴)以后。所有的点在第一个主成分上的值就固定了。这些点在第一个主成分上的这些取值,我们就不关心了。我们关心的是这些数据点剩下的信息,在其他的主成分上的取值。
这就是这页 PPT 讲的:
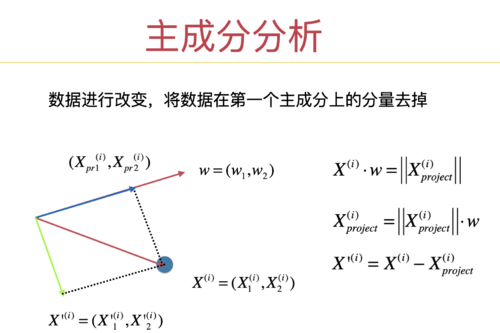
红色的向量(也就是原始数据)是数据的所有信息。
现在,我们求出了第一主成分,也就是红色的轴。那么红色的向量,在红色的轴上的映射,就是红色的向量,在这个主成分上的信息。也就是蓝色的向量。
但是,蓝色的向量不是红色的向量的完整信息。蓝色的向量和红色的向量之间差了什么?差了绿色的向量。(红色向量 - 蓝色向量 = 绿色向量。或者蓝色向量 + 绿色向量 = 红色向量)
所以后续,我们关注的是绿色的向量。
(你的大部分问题,似乎集中在这页 ppt 中。)
放到图示中,我们把所有蓝色点在第一主成分的轴中对应的分量去掉,就变成这个样子了:
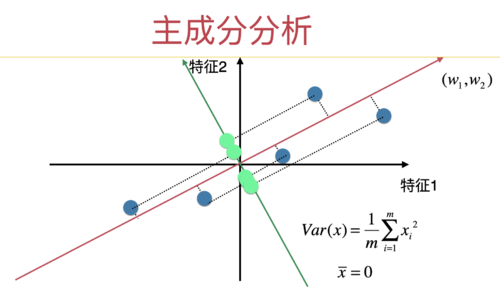
现在,所有的绿色的点才是我们关心的。我们要看要继续保留绿色的点的信息,把他们映射到哪根轴上最合适。而红色的轴,我们已经完全不管了。相当于我们直接扔掉了一维(红色的轴)。但因为现在我们整体就在二维空间,扔掉一维之后,就剩下一维了。所以很自然的,所有的绿色的点就在一个轴上,也就是绿色的轴,也就是此时的第二主成分。
==========
下面,我在三维空间中看这件事情,你或许会觉得更清晰。下面的截图,来自于这个 notebook:https://github.com/liuyubobobo/Play-with-Machine-Learning-Algorithms/blob/master/07-PCA-and-Gradient-Ascent/Optional-01-PCA-in-3d-Data/Optional-01-PCA-in-3d-Data.ipynb
我们随机生成三维点以后:
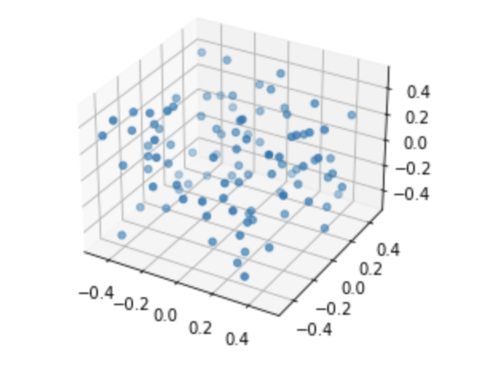
现在,我们可以根据这些点的信息,求出第一主成分。也就是第一个轴。那么你就可以想象,所有的点在这个轴上的映射,就是在第一主成分上的信息。
但关键是:第一主成分上的信息不是所有点的全部信息。我们要继续表达这些点的其他信息,怎么办?
那么这些点在第一主成分上的分量,我们已经不 care 了(因为已经固定了)。我们把这写点在第一主成分上的信息扔掉,你可以想象,所有的点将映射到一个平面上。这些点在这个平面上的信息,就是除了第一主成分以外,剩余的信息。就是这个样子的:
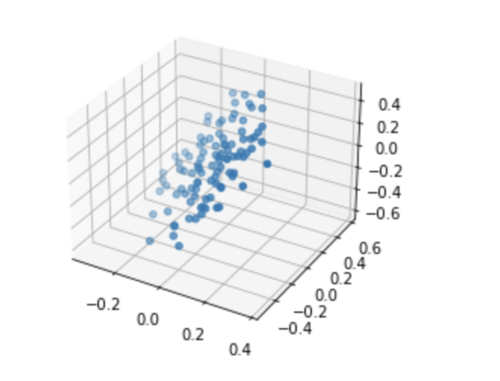
现在,我们的任务变成了:在这个平面上,找到“第一主成分”(也就是在原来是三维空间的第二主成分),能够最大化的保留这个平面上的点的信息。
至此,问题变成了和二维空间一致了。
找到了这个平面上的第一主成分(也就是整体的第二主成分以后),我们再把这个平面上的点在这个主成分上的分量扔掉(因为已经固定了,我们不 care 了,我们要看剩下的信息要怎么表达),得到的结果,就是所有的点映射到了一个直线上了。
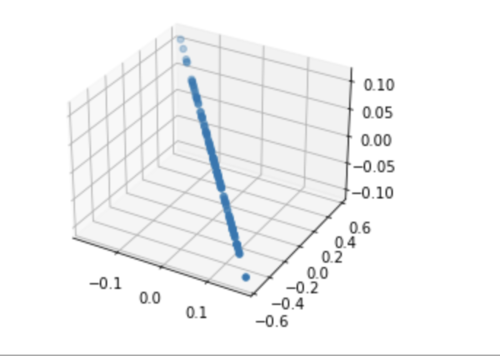
那么此时,就剩下一个维度了,这个维度就是最后的一个维度,所有点现在所在的直线,就是最后的一个主成分(最后一个轴。)
==========
推而广之:
如果在一个 n 维空间,你求出第一主成分以后,所有的数据在这个主成分上的分量就已经固定了,我们已经不 care 了。但是,所有数据在这个主成分上的分量不是全部的信息。还剩下的信息在哪里?把所有数据在这个主成分上的分量减去,得到的剩余信息,在一个 n - 1 维空间中。我们可以继续在这个 n - 1 维的空间中求第一主成分(也就是整体的第二主成分),这个过程依次类推。
看看你是否能理解?
继续加油!:)
672023-05-31











相似问题