RNN 训练的时候报错 对比源码没有发现什么问题。请求帮助
来源:4-34 动手实现RNN-LSTM循环神经网络(九):编写训练方法(下)

Hi_Mike
2019-11-22
训练错误信息:
Epoch 1, Step 0, Cost: 322.411, Accuracy: 0.000, Seconds per step: 0.000
Epoch 1, Step 50, Cost: 252.961, Accuracy: 0.030, Seconds per step: 1.500
Epoch 1, Step 100, Cost: 230.810, Accuracy: 0.040, Seconds per step: 1.480
Epoch 1, Step 150, Cost: 234.002, Accuracy: 0.074, Seconds per step: 1.480
Epoch 1, Step 200, Cost: 227.385, Accuracy: 0.080, Seconds per step: 1.460
Epoch 1, Step 250, Cost: 224.057, Accuracy: 0.087, Seconds per step: 1.460
Epoch 1, Step 300, Cost: 214.833, Accuracy: 0.123, Seconds per step: 1.480
Epoch 1, Step 350, Cost: 218.553, Accuracy: 0.124, Seconds per step: 1.460
Epoch 1, Step 400, Cost: 223.802, Accuracy: 0.099, Seconds per step: 1.460
Epoch 1, Step 450, Cost: 212.006, Accuracy: 0.126, Seconds per step: 5.580
Epoch 1, Step 500, Cost: 213.910, Accuracy: 0.116, Seconds per step: 1.900
Epoch 1, Step 550, Cost: 204.343, Accuracy: 0.151, Seconds per step: 1.800
Epoch 1, Step 600, Cost: 214.021, Accuracy: 0.124, Seconds per step: 1.780
Epoch 1, Step 650, Cost: 200.724, Accuracy: 0.143, Seconds per step: 1.780
Epoch 1, Step 700, Cost: 204.337, Accuracy: 0.136, Seconds per step: 1.720
Epoch 1, Step 750, Cost: 202.857, Accuracy: 0.147, Seconds per step: 1.640
Epoch 1, Step 800, Cost: 202.397, Accuracy: 0.141, Seconds per step: 1.640
Epoch 1, Step 850, Cost: 196.935, Accuracy: 0.167, Seconds per step: 1.640
Epoch 1, Step 900, Cost: 199.448, Accuracy: 0.151, Seconds per step: 1.640
Epoch 1, Step 950, Cost: 204.407, Accuracy: 0.151, Seconds per step: 1.640
Epoch 1, Step 1000, Cost: 195.622, Accuracy: 0.170, Seconds per step: 1.640
Epoch 1, Step 1050, Cost: 195.025, Accuracy: 0.173, Seconds per step: 1.640
Epoch 1, Step 1100, Cost: 198.898, Accuracy: 0.163, Seconds per step: 1.620
Epoch 1, Step 1150, Cost: 177.962, Accuracy: 0.207, Seconds per step: 1.620
Epoch 1, Step 1200, Cost: 190.201, Accuracy: 0.213, Seconds per step: 1.540
Epoch 1, Step 1250, Cost: 185.376, Accuracy: 0.221, Seconds per step: 1.640
Epoch 1, Step 1300, Cost: 196.294, Accuracy: 0.141, Seconds per step: 1.620
Epoch 2, Step 0, Cost: 203.552, Accuracy: 0.156, Seconds per step: 0.000
Traceback (most recent call last):
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/client/session.py”, line 1365, in _do_call
return fn(*args)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/client/session.py”, line 1350, in _run_fn
target_list, run_metadata)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/client/session.py”, line 1443, in _call_tf_sessionrun
run_metadata)
tensorflow.python.framework.errors_impl.OutOfRangeError: FIFOQueue ‘_0_input_producer’ is closed and has insufficient elements (requested 1, current size 0)
[[{{node input_producer_Dequeue}}]]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “33_train.py”, line 108, in
batch_size=20, model_save_name=‘train-checkpoint’)
File “33_train.py”, line 67, in train
feed_dict={m.init_state: current_state}
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/client/session.py”, line 956, in run
run_metadata_ptr)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/client/session.py”, line 1180, in _run
feed_dict_tensor, options, run_metadata)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/client/session.py”, line 1359, in _do_run
run_metadata)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/client/session.py”, line 1384, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.OutOfRangeError: FIFOQueue ‘_0_input_producer’ is closed and has insufficient elements (requested 1, current size 0)
[[node input_producer_Dequeue (defined at /Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/framework/ops.py:1748) ]]
Original stack trace for ‘input_producer_Dequeue’:
File “33_train.py”, line 108, in
batch_size=20, model_save_name=‘train-checkpoint’)
File “33_train.py”, line 16, in train
data=train_data)
File “/Users/yangjiayuan/Workspace/tensor_flow_practise/04/utils.py”, line 181, in init
num_steps)
File “/Users/yangjiayuan/Workspace/tensor_flow_practise/04/utils.py”, line 156, in generate_batches
i = tf.train.range_input_producer(epoch_size, shuffle=False).dequeue()
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/ops/data_flow_ops.py”, line 446, in dequeue
self._queue_ref, self._dtypes, name=name)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/ops/gen_data_flow_ops.py”, line 4140, in queue_dequeue_v2
timeout_ms=timeout_ms, name=name)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/framework/op_def_library.py”, line 794, in _apply_op_helper
op_def=op_def)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/util/deprecation.py”, line 507, in new_func
return func(*args, **kwargs)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/framework/ops.py”, line 3357, in create_op
attrs, op_def, compute_device)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/framework/ops.py”, line 3426, in _create_op_internal
op_def=op_def)
File “/Users/yangjiayuan/Workspace/virtualenv/Stockenv/lib/python3.7/site-packages/tensorflow_core/python/framework/ops.py”, line 1748, in init
self._traceback = tf_stack.extract_stack()
对应代码片段:
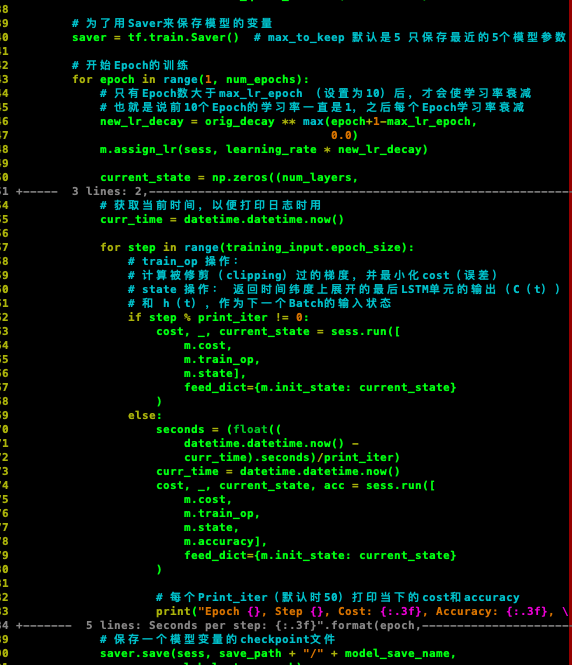
请问这是什么问题啊。老师!
diff 比较我两个文件 区别如下:
diff 33_train.py …/课程代码和素材(包含训练好的参数文件)/1.TensorFlow_Exercises/8.RNN/train.py 19-11-24 15:11
1,4c1,29
< #!/usr/bin/env python3
< # -- coding:utf-8 --
< # Author: Penguin
< # Created Time: 五 11/22 08:26:00 2019

-- coding: UTF-8 --
“”"
训练神经网络模型大家之后可以加上各种的 name_scope(命名空间)
用 TensorBoard 来可视化==== 一些术语的概念 ====
Batch size : 批次(样本)数目。一次迭代(Forword 运算(用于得到损失函数)以及 BackPropagation 运算(用于更新神经网络参数))所用的样本数目。Batch size 越大,所需的内存就越大
Iteration : 迭代。每一次迭代更新一次权重(网络参数),每一次权重更新需要 Batch size 个数据进行 Forward 运算,再进行 BP 运算
Epoch : 纪元/时代。所有的训练样本完成一次迭代
假如 : 训练集有 1000 个样本,Batch_size=10
那么 : 训练完整个样本集需要: 100 次 Iteration,1 个 Epoch
但一般我们都不止训练一个 Epoch
==== 超参数(Hyper parameter)====
init_scale : 权重参数(Weights)的初始取值跨度,一开始取小一些比较利于训练
learning_rate : 学习率,训练时初始为 1.0
num_layers : LSTM 层的数目(默认是 2)
num_steps : LSTM 展开的步(step)数,相当于每个批次输入单词的数目(默认是 35)
hidden_size : LSTM 层的神经元数目,也是词向量的维度(默认是 650)
max_lr_epoch : 用初始学习率训练的 Epoch 数目(默认是 10)
dropout : 在 Dropout 层的留存率(默认是 0.5)
lr_decay : 在过了 max_lr_epoch 之后每一个 Epoch 的学习率的衰减率,训练时初始为 0.93。让学习率逐渐衰减是提高训练效率的有效方法
batch_size : 批次(样本)数目。一次迭代(Forword 运算(用于得到损失函数)以及 BackPropagation 运算(用于更新神经网络参数))所用的样本数目
(batch_size 默认是 20。取比较小的 batch_size 更有利于 Stochastic Gradient Descent(随机梯度下降),防止被困在局部最小值)
"""
7c32
< from network_29 import *
from network import *
10,12c35,36
< def train(train_data, vocab_size, num_layers,
< num_epochs, batch_size, model_save_name, learning_rate=1.0,
< max_lr_epoch=10, lr_decay=0.93, print_iter=50):
def train(train_data, vocab_size, num_layers, num_epochs, batch_size, model_save_name,
learning_rate=1.0, max_lr_epoch=10, lr_decay=0.93, print_iter=50):
14,16c38
< training_input = Input(batch_size=batch_size,
< num_steps=35,
< data=train_data)
training_input = Input(batch_size=batch_size, num_steps=35, data=train_data)
19,23c41
< m = Model(training_input,
< is_training=True,
< hidden_size=650,
< vocab_size=vocab_size,
< num_layers=num_layers)
m = Model(training_input, is_training=True, hidden_size=650, vocab_size=vocab_size, num_layers=num_layers)
34c52
< # Coordinator(协调器),用于协调线程的运行
# Coordinator(协调器),用于协调线程的运行
39,40c57,58
< # 为了用Saver来保存模型的变量
< saver = tf.train.Saver() # max_to_keep 默认是5 只保存最近的5个模型参数
# 为了用 Saver 来保存模型的变量 saver = tf.train.Saver() # max_to_keep 默认是 5, 只保存最近的 5 个模型参数文件
42c60
< # 开始Epoch的训练
# 开始 Epoch 的训练
44,47c62,64
< # 只有Epoch数大于max_lr_epoch (设置为10)后,才会使学习率衰减
< # 也就是说前10个Epoch的学习率一直是1,之后每个Epoch学习率衰减
< new_lr_decay = orig_decay ** max(epoch+1-max_lr_epoch,
< 0)
# 只有 Epoch 数大于 max_lr_epoch(设置为 10)后,才会使学习率衰减 # 也就是说前 10 个 Epoch 的学习率一直是 1, 之后每个 Epoch 学习率都会衰减 new_lr_decay = orig_decay ** max(epoch + 1 - max_lr_epoch, 0)
50,53c67,72
< current_state = np.zeros((num_layers,
< 2,
< batch_size,
< m.hidden_size))
# 当前的状态 # 第二维是 2 是因为对每一个 LSTM 单元有两个来自上一单元的输入: # 一个是 前一时刻 LSTM 的输出 h(t-1) # 一个是 前一时刻的单元状态 C(t-1) current_state = np.zeros((num_layers, 2, batch_size, m.hidden_size))
57,64c76,78
< print(“new_lr_decay: %f” % new_lr_decay)
< print(“epoch : %d” % epoch)
<
< for step in range(100):
< # train_op 操作:
< # 计算被修剪(clipping)过的梯度,并最小化cost(误差)
< # state 操作: 返回时间纬度上展开的最后LSTM单元的输出(C(t))
< # 和 h(t),作为下一个Batch的输入状态
for step in range(training_input.epoch_size): # train_op 操作:计算被修剪(clipping)过的梯度,并最小化 cost(误差) # state 操作:返回时间维度上展开的最后 LSTM 单元的输出(C(t) 和 h(t)),作为下一个 Batch 的输入状态
66,71c80
< cost, _, current_state = sess.run([
< m.cost,
< m.train_op,
< m.state],
< feed_dict={m.init_state: current_state}
< )
cost, _, current_state = sess.run([m.cost, m.train_op, m.state], feed_dict={m.init_state: current_state})
73,75c82
< seconds = (float((
< datetime.datetime.now() -
< curr_time).seconds)/print_iter)
seconds = (float((datetime.datetime.now() - curr_time).seconds) / print_iter)
77,101c84,95
< cost, _, current_state, acc = sess.run([
< m.cost,
< m.train_op,
< m.state,
< m.accuracy],
< feed_dict={m.init_state: current_state}
< )
<
< # 每个Print_iter(默认时50)打印当下的cost和accuracy
< print(“Epoch {}, Step {}, Cost: {:.3f}, Accuracy: {:.3f},
< Seconds per step: {:.3f}”.format(epoch,
< step,
< cost,
< acc,
< seconds))
< # 保存一个模型变量的checkpoint文件
< saver.save(sess, save_path + “/” + model_save_name,
< global_step=epoch)
<
< # 对模型做一次总的保存
< saver.save(sess, save_path + “/” + model_save_name + “-final”)
<
< # 关闭线程
< coord.request_stop()
< coord.join(threads)
cost, _, current_state, acc = sess.run([m.cost, m.train_op, m.state, m.accuracy], feed_dict={m.init_state: current_state}) # 每 print_iter(默认是 50)打印当下的 Cost(误差/损失)和 Accuracy(精度) print("Epoch {}, 第 {} 步, 损失: {:.3f}, 精度: {:.3f}, 每步所用秒数: {:.2f}".format(epoch, step, cost, acc, seconds)) # 保存一个模型的变量的 checkpoint 文件 saver.save(sess, save_path + '/' + model_save_name, global_step=epoch) # 对模型做一次总的保存 saver.save(sess, save_path + '/' + model_save_name + '-final') # 关闭线程 coord.request_stop() coord.join(threads)
107,108c101
< train_data, valid_data, test_data,
< vocab_size, id_to_word = load_data(data_path)
train_data, valid_data, test_data, vocab_size, id_to_word = load_data(data_path)
110,111c103,104
< train(train_data, vocab_size, num_layers=2, num_epochs=70,
< batch_size=20, model_save_name=‘train-checkpoint’)
train(train_data, vocab_size, num_layers=2, num_epochs=70, batch_size=20, model_save_name='train-checkpoint')
3回答
-

Oscar
2019-11-24
你把你的代码片段都贴在这个上面呗,不要贴截图,我不好查问题。谢谢
10 -

Hi_Mike
提问者
2019-11-24
diff 比较 发现 代码索近问题 最后几行 代码缩近出错 犯了低级错误。?!感谢老师及时回复。
new_lr_decay: 1.000000
epoch : 0
Epoch 0, Step 0, Cost: 322.160, Accuracy: 0.000, Seconds per step: 0.000
Epoch 0, Step 50, Cost: 249.785, Accuracy: 0.050, Seconds per step: 3.340
new_lr_decay: 1.000000
epoch : 1
Epoch 1, Step 0, Cost: 236.009, Accuracy: 0.050, Seconds per step: 0.000
Epoch 1, Step 50, Cost: 235.396, Accuracy: 0.064, Seconds per step: 2.920
new_lr_decay: 1.000000
epoch : 2
Epoch 2, Step 0, Cost: 227.338, Accuracy: 0.076, Seconds per step: 0.000
Epoch 2, Step 50, Cost: 222.950, Accuracy: 0.109, Seconds per step: 2.980
new_lr_decay: 1.000000
epoch : 3
Epoch 3, Step 0, Cost: 216.419, Accuracy: 0.104, Seconds per step: 0.000
现在能正常训练了。
012019-11-24 -
Hi_Mike
提问者
2019-11-24
<Mac> cat 33_train.py 19-11-24 15:09 #!/usr/bin/env python3 # -*- coding:utf-8 -*- # Author: Penguin # Created Time: 五 11/22 08:26:00 2019 from utils import * from network_29 import * def train(train_data, vocab_size, num_layers, num_epochs, batch_size, model_save_name, learning_rate=1.0, max_lr_epoch=10, lr_decay=0.93, print_iter=50): # 训练的输入 training_input = Input(batch_size=batch_size, num_steps=35, data=train_data) # 创建训练的模型 m = Model(training_input, is_training=True, hidden_size=650, vocab_size=vocab_size, num_layers=num_layers) # 初始化变量的操作 init_op = tf.global_variables_initializer() # 初始的学习率(learning rate)的衰减率 orig_decay = lr_decay with tf.Session() as sess: sess.run(init_op) # 初始化所有变量 # Coordinator(协调器),用于协调线程的运行 coord = tf.train.Coordinator() # 启动线程 threads = tf.train.start_queue_runners(coord=coord) # 为了用Saver来保存模型的变量 saver = tf.train.Saver() # max_to_keep 默认是5 只保存最近的5个模型参数 # 开始Epoch的训练 for epoch in range(num_epochs): # 只有Epoch数大于max_lr_epoch (设置为10)后,才会使学习率衰减 # 也就是说前10个Epoch的学习率一直是1,之后每个Epoch学习率衰减 new_lr_decay = orig_decay ** max(epoch+1-max_lr_epoch, 0) m.assign_lr(sess, learning_rate * new_lr_decay) current_state = np.zeros((num_layers, 2, batch_size, m.hidden_size)) # 获取当前时间,以便打印日志时用 curr_time = datetime.datetime.now() print("new_lr_decay: %f" % new_lr_decay) print("epoch : %d" % epoch) for step in range(100): # train_op 操作: # 计算被修剪(clipping)过的梯度,并最小化cost(误差) # state 操作: 返回时间纬度上展开的最后LSTM单元的输出(C(t)) # 和 h(t),作为下一个Batch的输入状态 if step % print_iter != 0: cost, _, current_state = sess.run([ m.cost, m.train_op, m.state], feed_dict={m.init_state: current_state} ) else: seconds = (float(( datetime.datetime.now() - curr_time).seconds)/print_iter) curr_time = datetime.datetime.now() cost, _, current_state, acc = sess.run([ m.cost, m.train_op, m.state, m.accuracy], feed_dict={m.init_state: current_state} ) # 每个Print_iter(默认时50)打印当下的cost和accuracy print("Epoch {}, Step {}, Cost: {:.3f}, Accuracy: {:.3f}, \ Seconds per step: {:.3f}".format(epoch, step, cost, acc, seconds)) # 保存一个模型变量的checkpoint文件 saver.save(sess, save_path + "/" + model_save_name, global_step=epoch) # 对模型做一次总的保存 saver.save(sess, save_path + "/" + model_save_name + "-final") # 关闭线程 coord.request_stop() coord.join(threads) if __name__ == "__main__": if args.data_path: data_path = args.data_path train_data, valid_data, test_data, \ vocab_size, id_to_word = load_data(data_path) train(train_data, vocab_size, num_layers=2, num_epochs=70, batch_size=20, model_save_name='train-checkpoint')00

相似问题