报错显存不够
来源:4-7 利用神经网络解决分类和回归问题(5)

一个很坏的好人
2020-05-30
在没加入测试代码的时候是正常运行的,运行时显存占用如下:
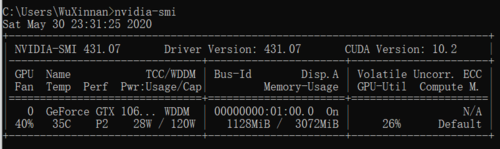
但是加入测试部分后,报错显存不足
训练集60000个数据才占用了1G显存,没道理测试集10000个数据显存就不够了啊
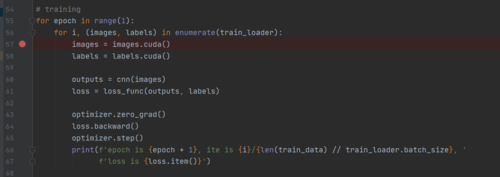
我在调试的时候发现,每次经过73,74行的时候,占用的显存都会增加,直到撑爆3G报错,而每次经过57,58行的时候,占用的显存都是固定的1128M,是不是代码哪里有问题啊,没有释放images和labels占用的空间?

我的完整代码:
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.utils.data as data_utils
# data
train_data = dataset.MNIST(root='mnist',
train=True,
transform=transforms.ToTensor(),
download=True)
test_data = dataset.MNIST(root='mnist',
train=False,
transform=transforms.ToTensor(),
download=False)
# batch_size
train_loader = data_utils.DataLoader(dataset=train_data,
batch_size=64,
shuffle=True)
test_loader = data_utils.DataLoader(dataset=test_data,
batch_size=64,
shuffle=True)
# net
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv = torch.nn.Sequential(
torch.nn.Conv2d(1, 32, kernel_size=5, padding=2),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.fc = torch.nn.Linear(14 * 14 * 32, 10)
def forward(self, x):
out = self.conv(x)
out = out.view(out.size()[0], -1)
out = self.fc(out)
return out
cnn = CNN()
cnn = cnn.cuda()
# loss
loss_func = torch.nn.CrossEntropyLoss()
# optimizer
optimizer = torch.optim.Adam(cnn.parameters(), lr=0.01)
# training
for epoch in range(1):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda()
labels = labels.cuda()
outputs = cnn(images)
loss = loss_func(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'epoch is {epoch + 1}, ite is {i}/{len(train_data) // train_loader.batch_size}, '
f'loss is {loss.item()}')
# eval/test
loss_test = 0
accuracy = 0
for i, (images, labels) in enumerate(test_loader):
images = images.cuda()
labels = labels.cuda()
outputs = cnn(images)
# labels的维度:batch_size
# outputs的维度:batch_size * cls_num,这里cls_num=10
loss_test += loss_func(outputs, labels)
_, pred = outputs.max(1)
accuracy += (pred == labels).sum().item()
accuracy = accuracy / len(test_data)
loss_test = loss_test / (len(test_data) // 64)
print(f'epoch is {epoch+1}, accuracy is {accuracy}, '
f'loss_test is {loss_test.item()}')
# save
# load
# inference写回答
1回答
-

会写代码的好厨师
2020-05-31
并不是说60000个样本占用显存会比10000个多,占用显存量看batchsize大小,这里训练集和测试集batch大小一样,所以到70几行会翻倍,可以把测试的batchsize改小,就应该可以了。
022020-11-20
