知乎首页-question链接提取问题
来源:6-16 item loder方式提取question - 3

慕先生0421411
2017-05-02


老师您好,请教一个问题:
图1您写的回调代码,实现起来好像不是很理想
图2是我发现的一个规律,当知乎首页右侧的下拉菜单拉到底后会自动加载出新的页面,抓包看到是通过post提交,当offset,start每次加10就会加载新的页面。
需求:是不是可以通过图2这种方式来多提取question链接,如果可以,是一个什么样的思路。
写回答
3回答
-
亲 你这个思路是没有问题的,因为考虑到课程的复杂性所以前面这部分我讲的比较简单, 实际上后面selenium中有讲到关于如何模拟鼠标下拉,也可以获取更多的链接, 在这一章中我会讲解到获取到answer, 和你现在遇到的问题很类似, 你可以参考一下本章后面的小节, 大概意思就是在获取到所有的url之后,你自己去拼凑url然后yield request 回调函数写为parse就行了
022017-05-24 -

bobby
2017-05-25
请求不了内容是什么意思?是没有进入parse函数吗, 而且你这里写成了parsea, 是拼写出错了吧
00 -

慕先生0421411
提问者
2017-05-24
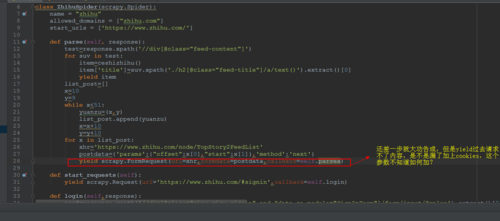
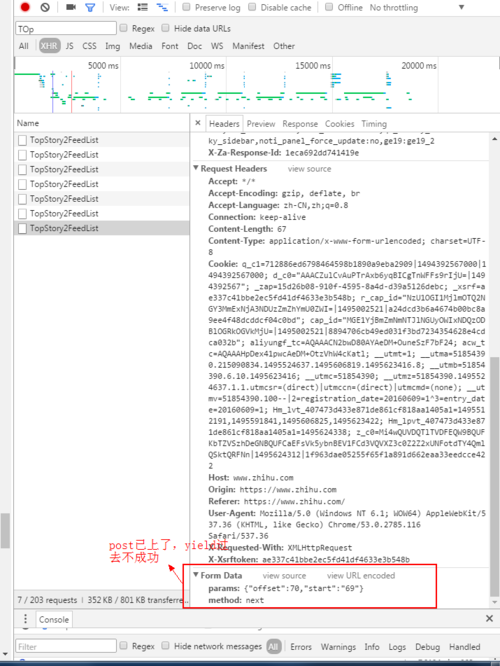
请问老师在yield里面还需要加上什么参数才能成功请求到动态加载的页面?
00



相似问题