老师所以k=6的意义是什么呢
来源:4-1 k近邻算法基础

SomnusL
2020-01-16
之前都听得懂,k=6之后后面的操作没太明白都是在干啥。。。而且为什么k要=6
2回答
-
你理解的 knn 的过程是正确的。
k = 6 只是我们暂时取的一个值,k 被称为是超参数。对于这一点,课程后续会介绍的。
x_train 是一个向量,代表一个样本。注意下面的程序中:

x_train 是从 X_train 中取出来的。X_train 是一个二维数组,x_train 是这个二维数组中的一行。大写的 X 代表二维矩阵,小写的 x 代表向量。印象里课程中讲过,在这整个课程中,变量名称都遵循这个原则。这样通过变量名,就能看出来,当前变量代表的到底是向量还是矩阵。
实际在程序中打印出来 x_train,看一看这个 x_train 到底是什么?
x 当然被定义过。不仅定义了,我们还将它可视化了。下面蓝色的点就是 x。

你最后的问题,我没有可能明白你想怎么写。把你想写的逻辑实际写出来,实际运行一下,看看得到的结果是什么意思?和你想的是否一样?如果不一样,问题出在哪里?再仔细体会一下,课程中的逻辑,求得是什么?
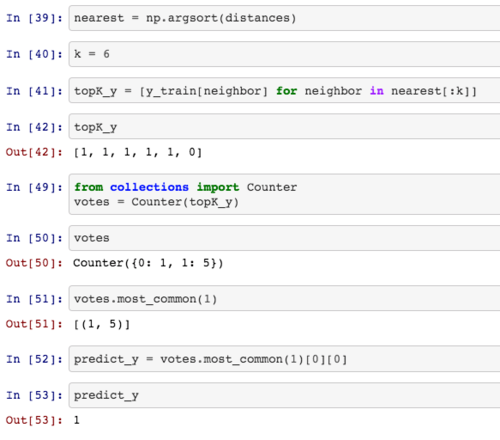
答案:课程中的逻辑,求得是离 x 最近的六个点,对应的 y 值是多少,分别是 1 1 1 1 1 0,因为有 5 个 1,1 个 0,1 的数量多,所以我们预测 x 属于 1 这个类别。
根据上面的回答,再重新看一遍这一小节?要理解我们写的每一行代码到底在干什么,求得是什么。
继续加油!:)
132020-01-17 -

SomnusL
提问者
2020-01-17
啊 我搞懂了。过程就是先把两个数据集存入array 然后绘制当y是0和1的前两列在x和y上的散点分布图。给出要预测的那一个数据,把数据加到表格上,用欧拉公式算出预测点和所有点之间的距离,然后用排序找出索引,然后找出k个理他最近的数据nearest中前k个元素在Y-train 中对应的是1还是0然后再用counter统计出现次数最多的元素是0还是1. 试着思路吗?
但是还有点没明白为什么在算距离的时候直接就(x_train-x)可以这样写?x_train不是代表所有的点的坐标吗?之前也没定义过它代表什么啊?为啥可以这样写呢,而且x之前也没有被定义过啊。
还有就是找出离预测点最近的点的y坐标不应该是for nearest in Y_train吗?为啥是Y train in nearest。。。00




相似问题
回答 1
回答 1
回答 1
回答 1
回答 2